
Aloys Build Manual
Aloys的环境搭建手册
Windows信息:
将要配置的集群信息: 利用Virtualbox,安装三台Ubuntu 16.04.1版本的虚拟机,其中一台担任DataNode、SecondaryNameNode、ResourceManager的角色,另外两台担任DataNode、NodeManager的角色。具体组网如下:
| 主机名 | IP | 掩码 | 网关 | DNS服务器 | 角色 |
|---|---|---|---|---|---|
| DESKTOP-LSB0HI4 | 192.168.1.100 | 255.255.255.0 | 192.168.1.1 | 114.114.114.114 | 主机 |
| Ubuntu-01 | 192.168.1.160 | 255.255.255.0 | 192.168.1.1 | 114.114.114.114 | DataNode/SecondaryNameNode/ResourceManager/master/worker/zookeeper/HMaster/hive/pig |
| Ubuntu-02 | 192.168.1.170 | 255.255.255.0 | 192.168.1.1 | 114.114.114.114 | DataNode/NodeManager/worker/zookeeper/HRegion |
| Ubuntu-03 | 192.168.1.180 | 255.255.255.0 | 192.168.1.1 | 114.114.114.114 | DataNode/NodeManager/ worker/zookeeper/HRegion |
安装VirtualBox
首先需要在主机中安装虚拟机VirtualBox,此次我安装的版本为VirtualBox-5.1.14-112924-Win。
下载地址:https://www.virtualbox.org/
单机VirtualBox-5.1.14-112924-Win.exe,按照所给的说明进行安装:
安装Linux(Ubuntu)
安装Virtualbox之后,需要在其中安装Linux服务器。我使用的Linux发行版本为:ubuntu-16.04.1-desktop-amd64。
下载地址:https://www.ubuntu.com/download
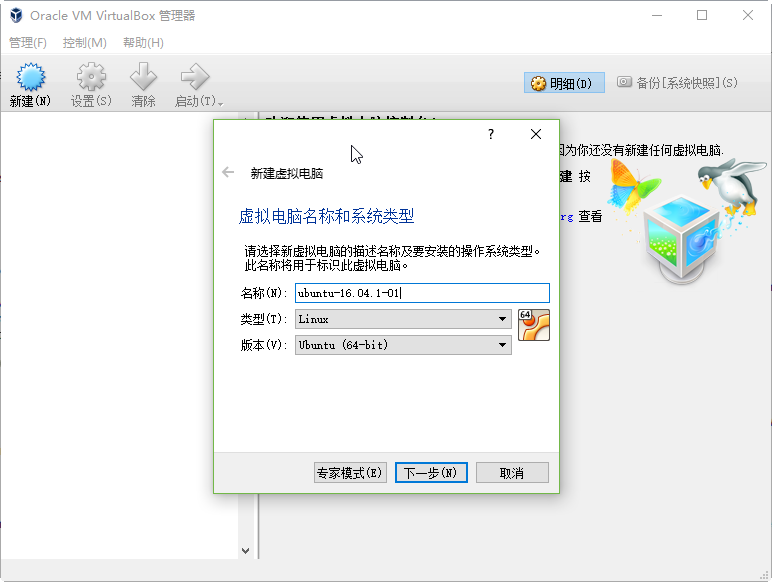
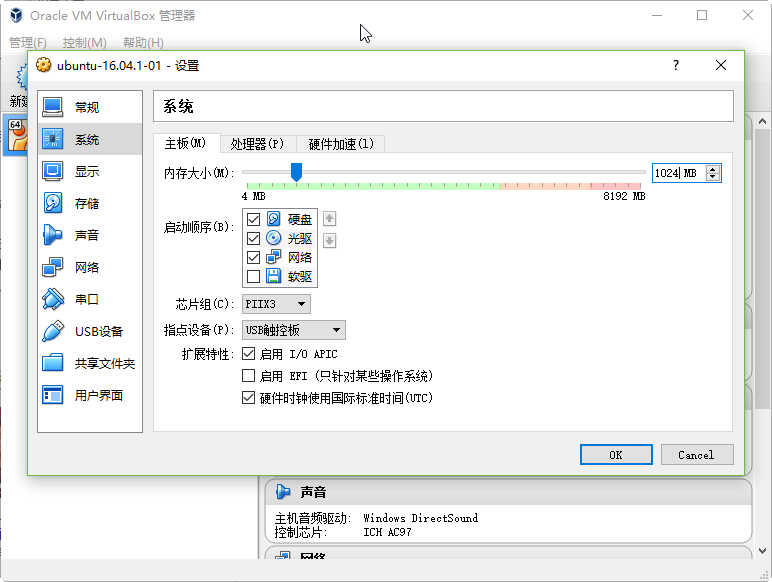
此处需要为虚拟机分配内存大小,建议内存充足的朋友多分配一些。此处我分配了512MB内存,但是之后又修改为1024MB。
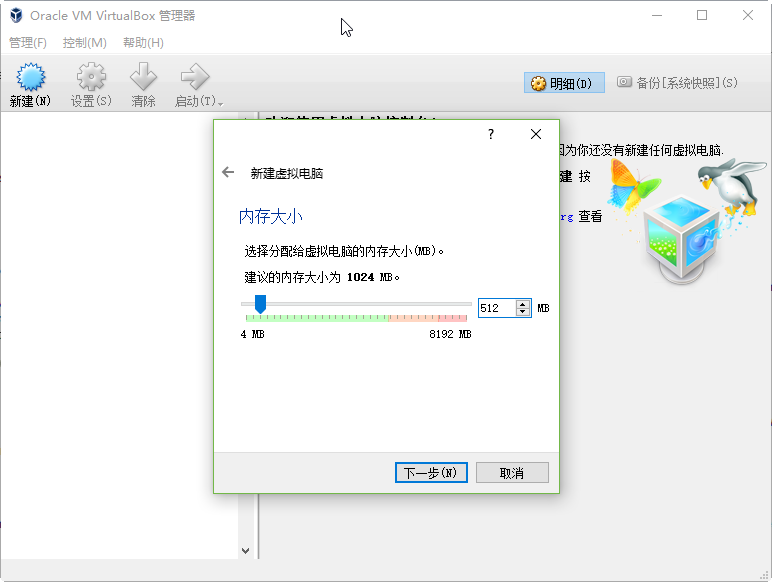
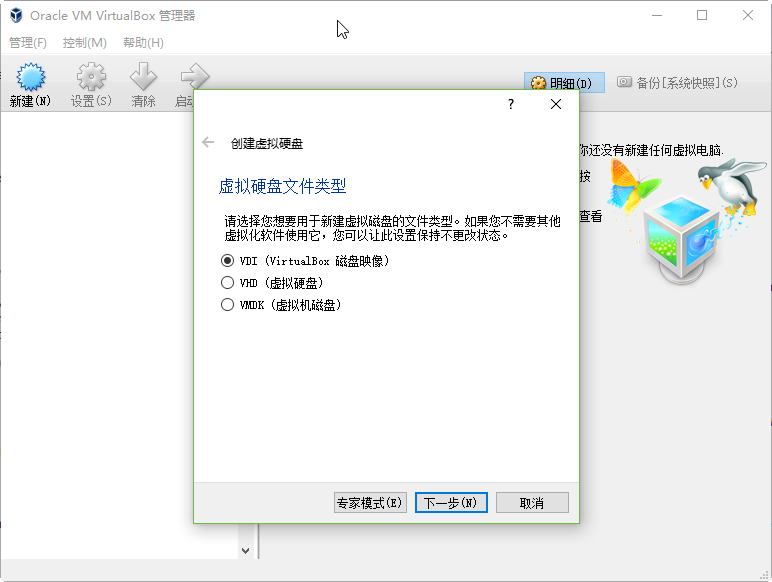
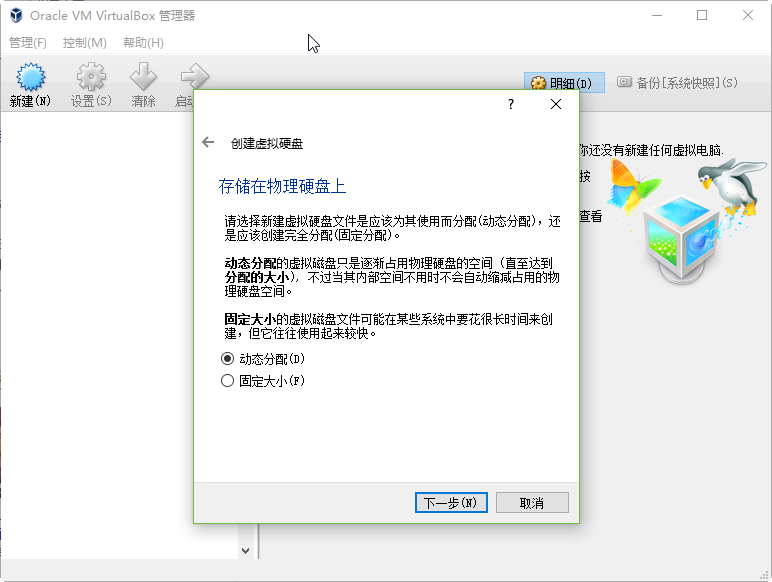
此处需要分配虚拟机的硬盘容量,请硬盘容量充足的朋友多分配一些。另外虚拟硬盘最好存储在SSD这样的高速存取设备上,提升虚拟机相应速度。
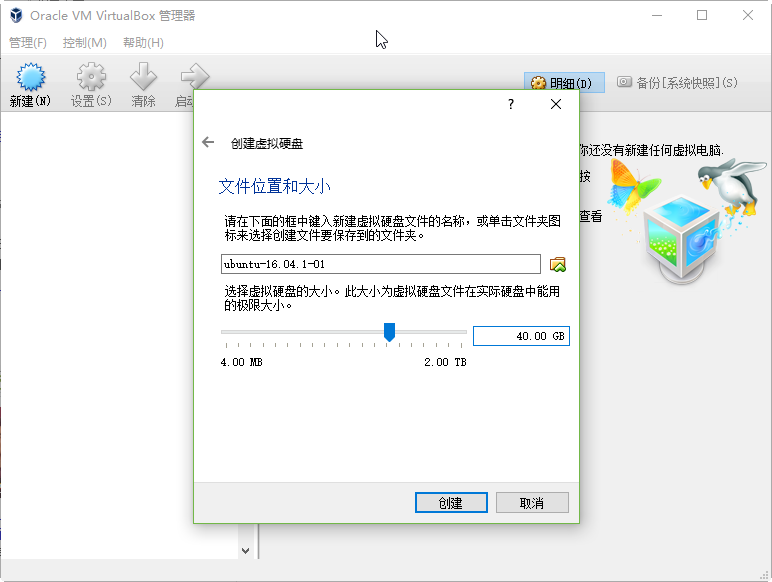
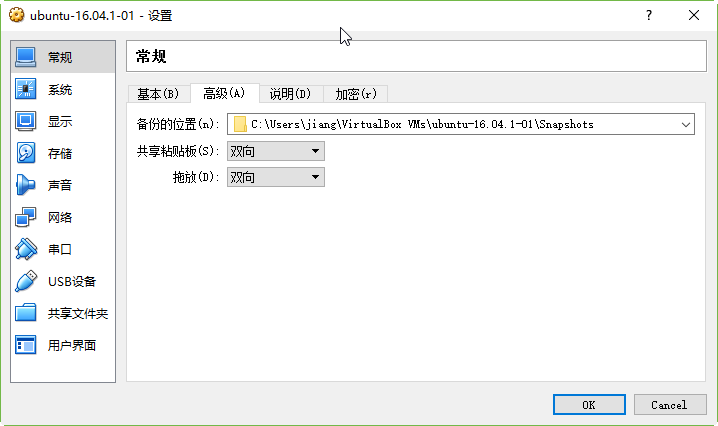
将共享剪贴板和拖放功能均选为双向:
此处将虚拟机内存修改为1024MB。
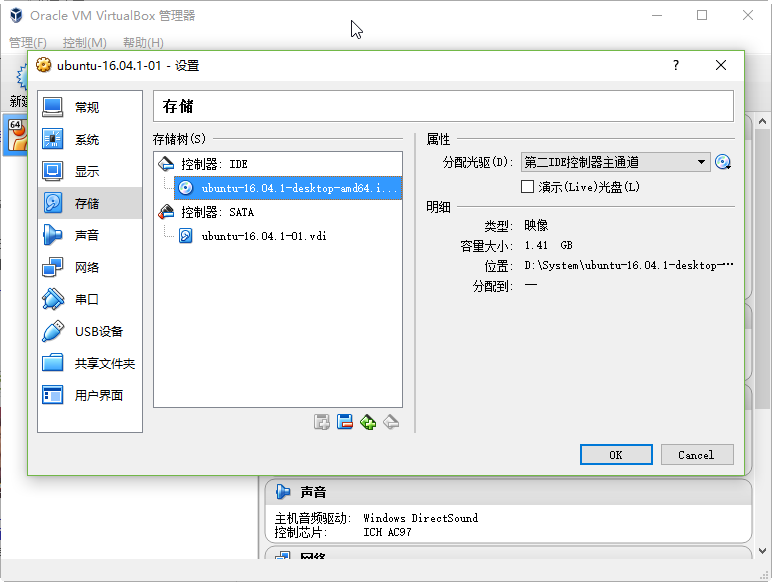
点击右侧的关盘图标,选择我们之前下载的ubuntu-16.04.1-desktop-amd64.iso
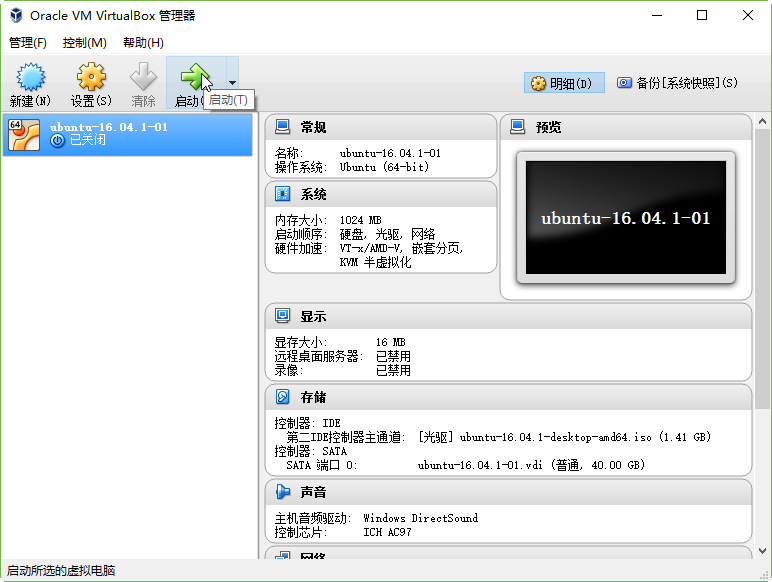
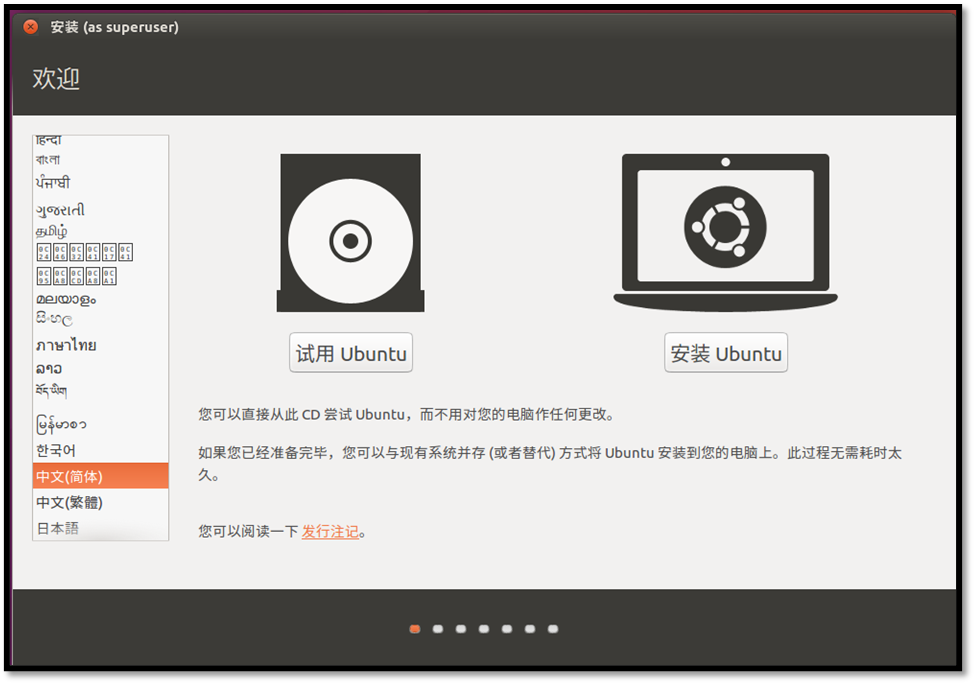
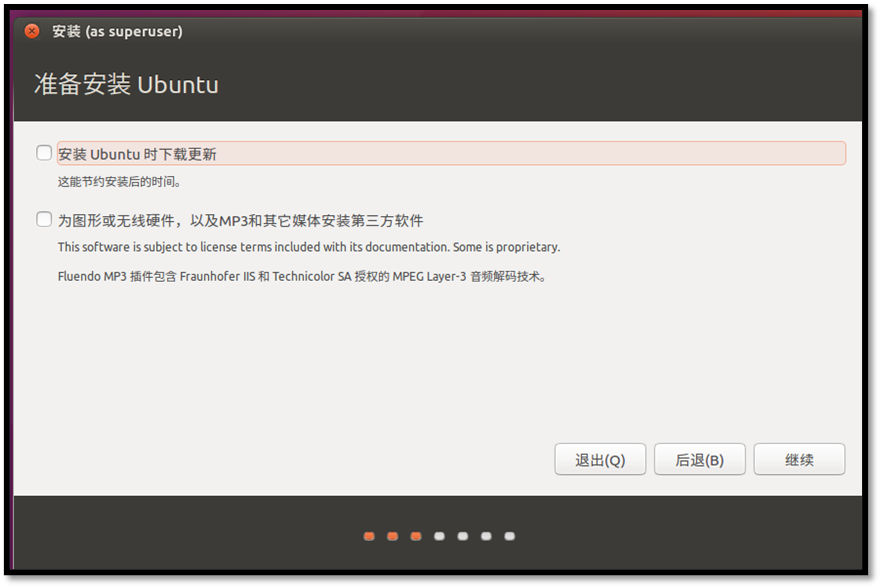
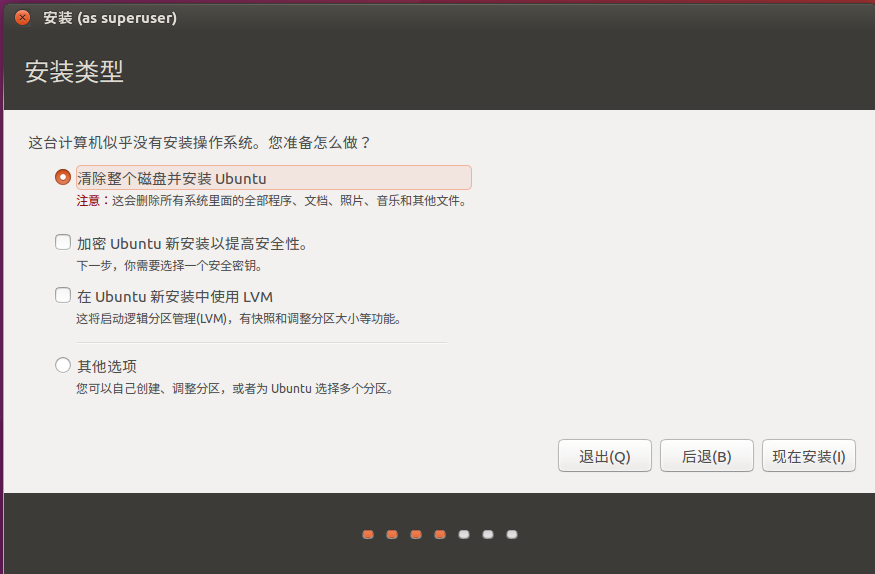
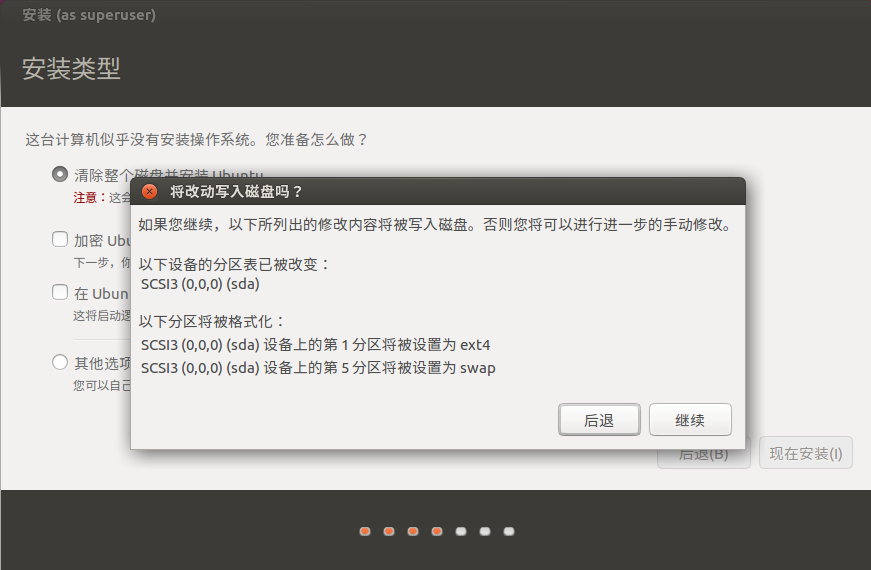
复制虚拟机
安装Ubuntu-16.04.1-01之后,复制该虚拟机,创建Ubuntu-16.04.1-02、Ubuntu-16.04.1-03
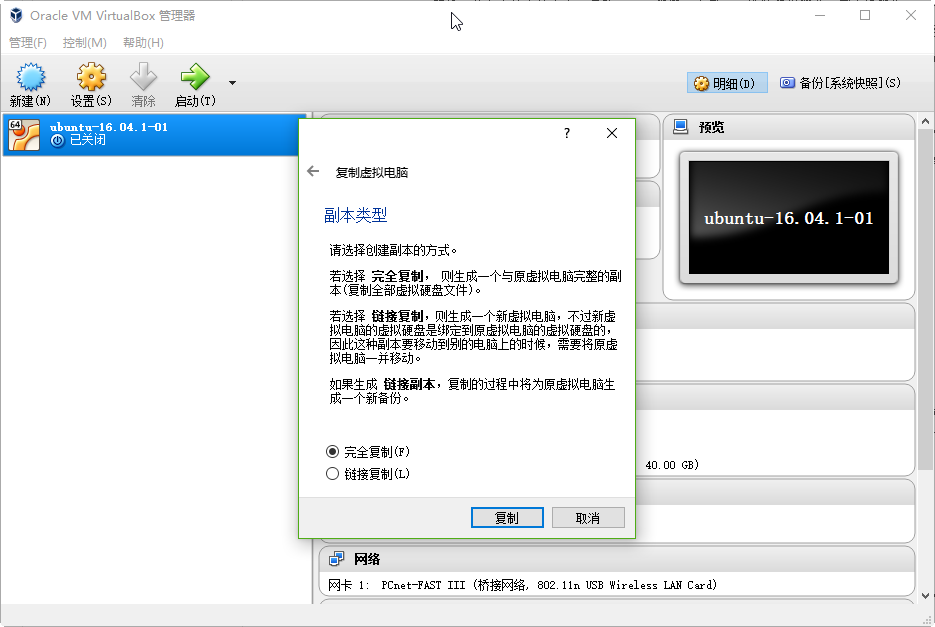
复制之后效果如下图:
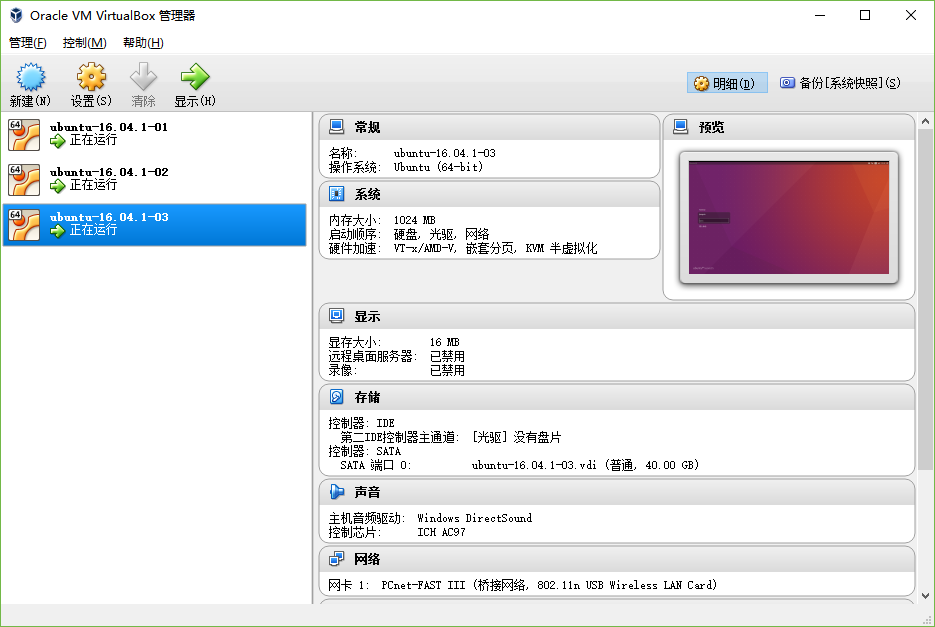
配置各个虚拟机
hadoop@Ubuntu-01:~$ sudo apt-get install lrzsz
hadoop@Ubuntu-01:~$ sudo apt-get install vim
配置网络
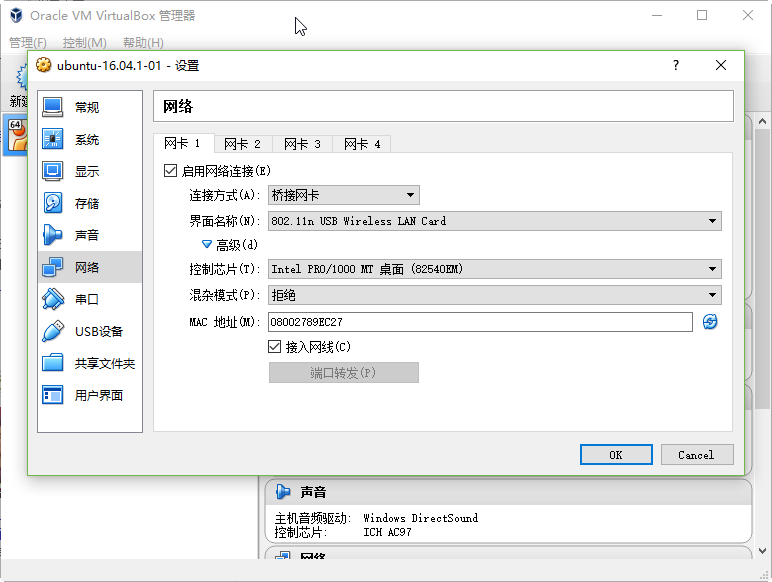
将服务器的IP分配方式改为固定IP,点击系统设置-网络-选项-IPv4设置。按照下图进行设置。注意不要忘了DNS服务器的配置,否则会导致虚拟机无法上外网。
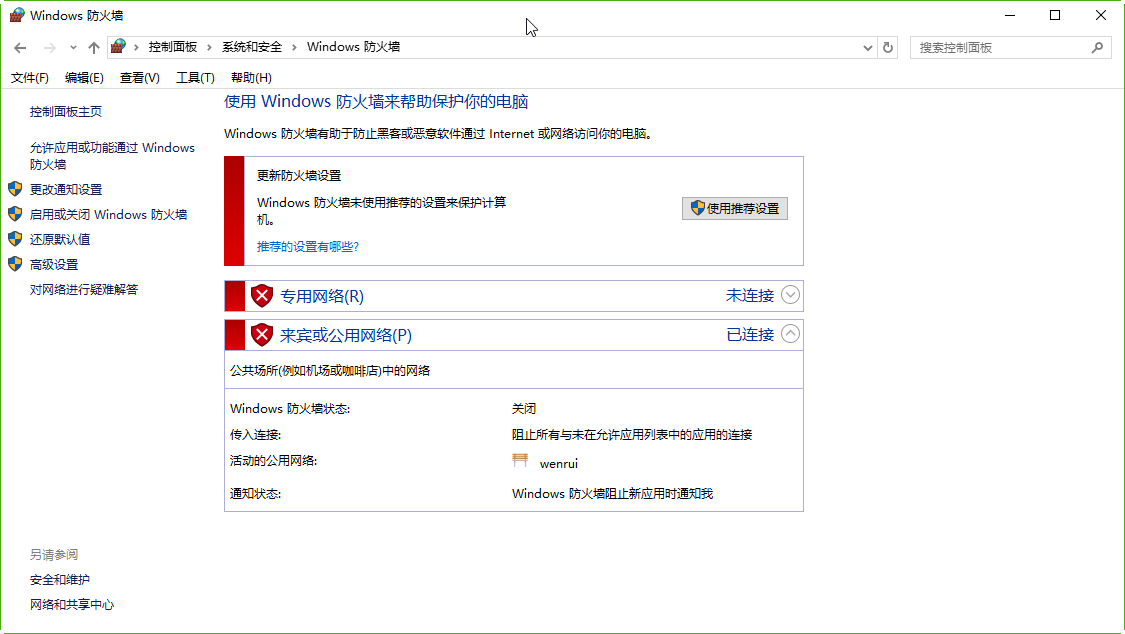
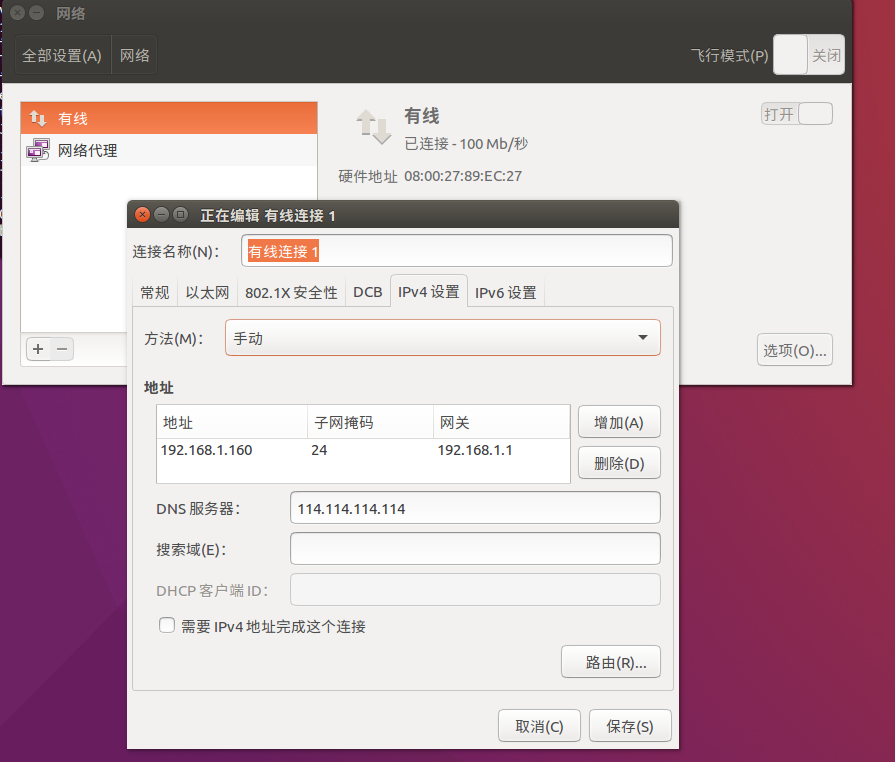 配置完网络之后,尝试主机和虚拟机互相ping,如果均能ping同则说明网络配置正常。否则需要检查防火墙等配置。此次安装过程中,主机可以ping通虚拟机,但是虚拟机无法ping通主机。关闭Windows机器防火墙后,问题解决。
配置完网络之后,尝试主机和虚拟机互相ping,如果均能ping同则说明网络配置正常。否则需要检查防火墙等配置。此次安装过程中,主机可以ping通虚拟机,但是虚拟机无法ping通主机。关闭Windows机器防火墙后,问题解决。
安装openssh-server
为了之后方便主机与虚拟机之间,以及各个虚拟机之间方便通讯,需要在虚拟机中安装openssh-server。(Ubuntu默认已经安装SSH Client)
sudo apt-get install openssh-server
安装之后就可以在Windows主机上利用XShell登陆各个虚拟机。
开启root用户
在之后的某些操作中(比如文件传输)经常需要root用户,但是Ubuntu默认是不开启root用户的,使用下面的命令进行开启: sudo passwd root
修改主机名
复制的虚拟机的主机名均为Ubuntu-01,但为了以后集群中能够容易分辨各台服务器,需要给每台机器取个不同的名字。机器名由 /etc/hostname文件决定。 sudo vim /etc/hostname
在三台虚拟机上,分别配置为: Ubuntu-01 Ubuntu-02 Ubuntu-03 重启三台虚拟机(sudo reboot),重新利用XShell进行登录,效果如下:



修改hosts
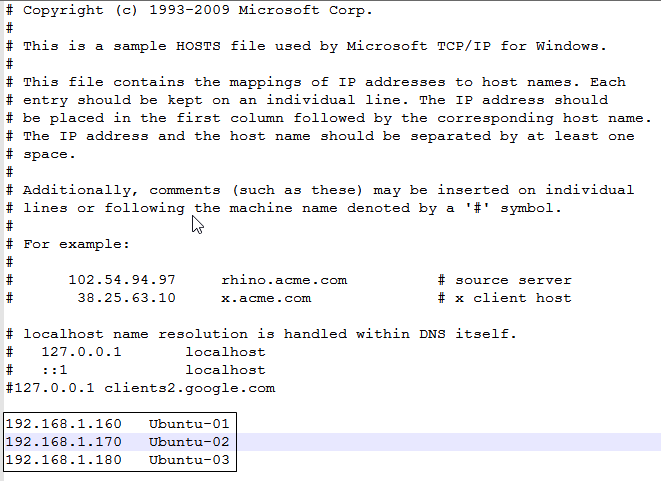
为了让主机与各个虚拟机以及各个虚拟机之间通讯更加方便,需要配置主机和三台虚拟机的hosts文件:
Windows主机(C:\windows\system32\drivers\etc)
Ubuntu-01(/etc/hosts)
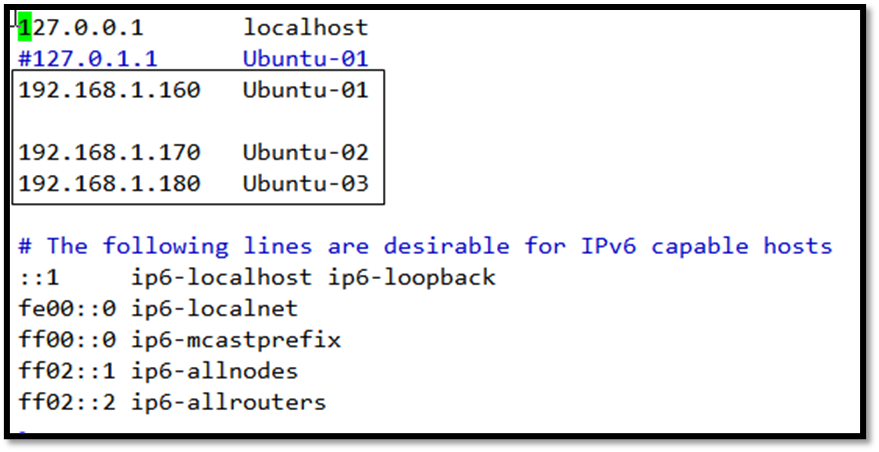
Ubuntu-02(/etc/hosts)
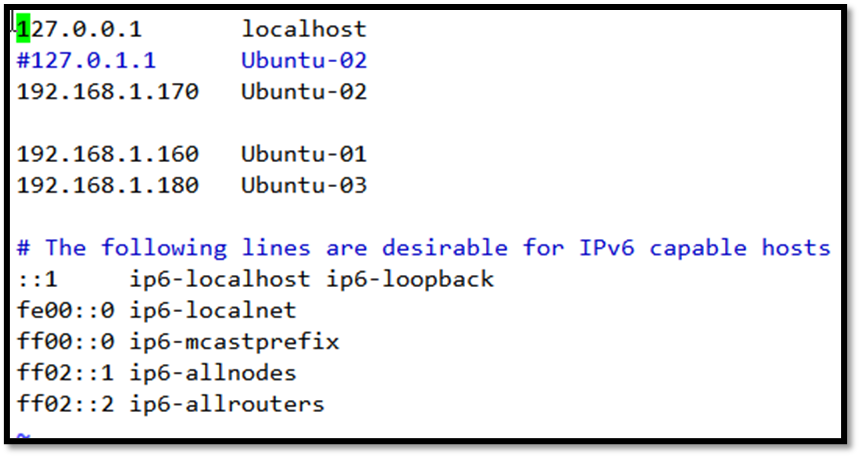
Ubuntu-03(/etc/hosts)
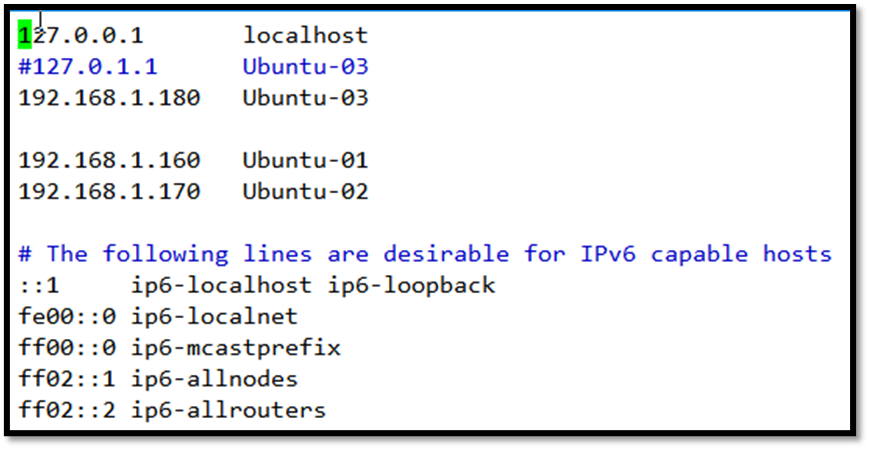
修改之前效果:

修改之后效果:
创建hadoop用户组和用户

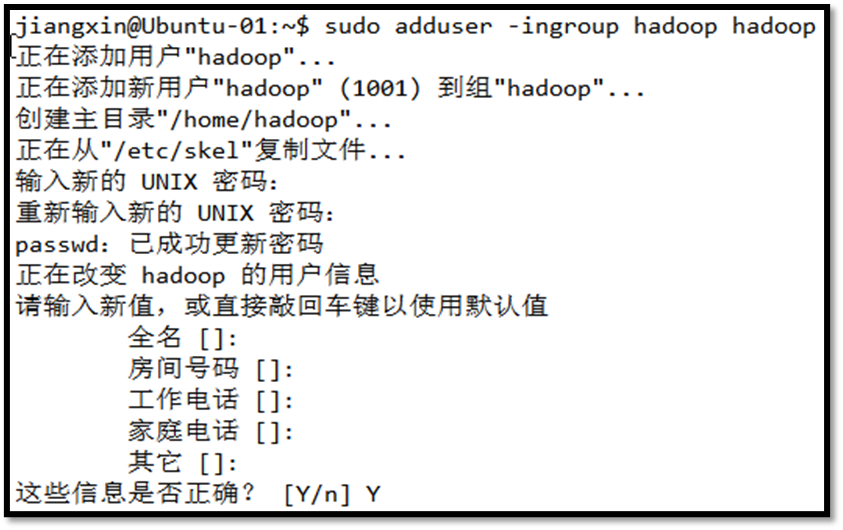
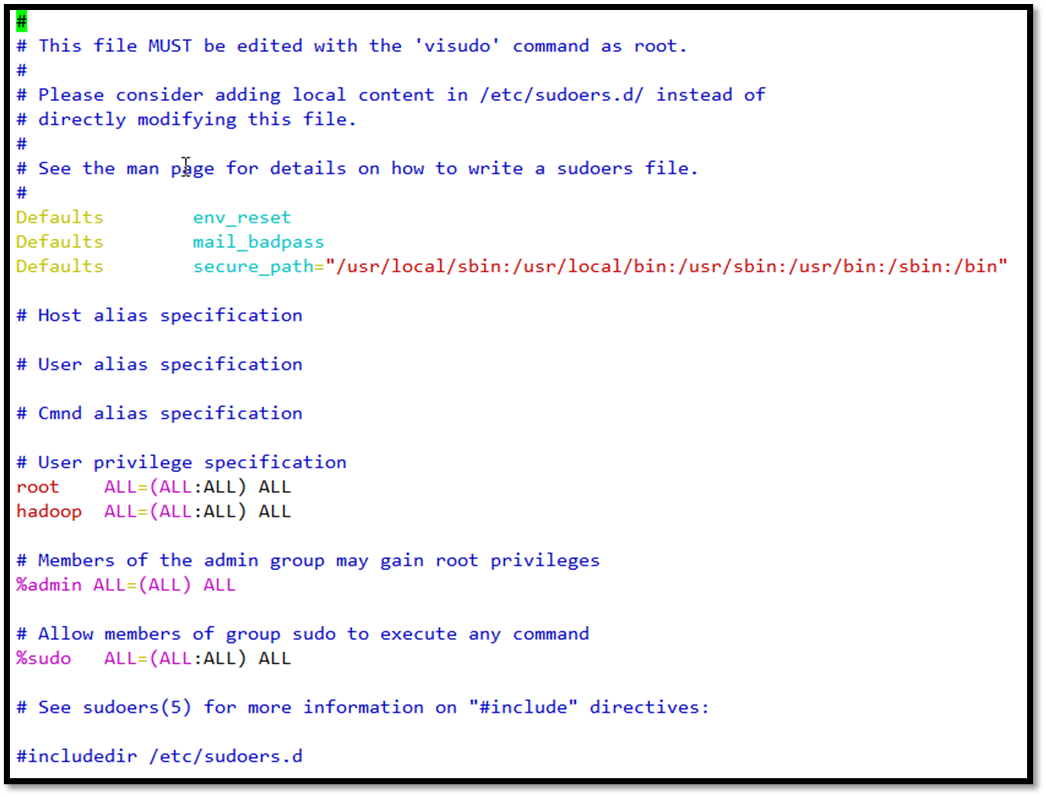
另外还需要给hadoop用户添加权限,打开/etc/sudoers文件,在root ALL=(ALL:ALL) ALL下添加hadoop ALL=(ALL:ALL) ALL,
创建hadoop用户之后,su到hadoop用户,进行后续操作。本文之后的所有操作,如无特殊说明均是指在hadoop用户下。
配置ssh免登陆
为了完成分布式计算系统,需要三台机器相互之间可以无密码访问(或者是master可以无密码访问2个slave)。
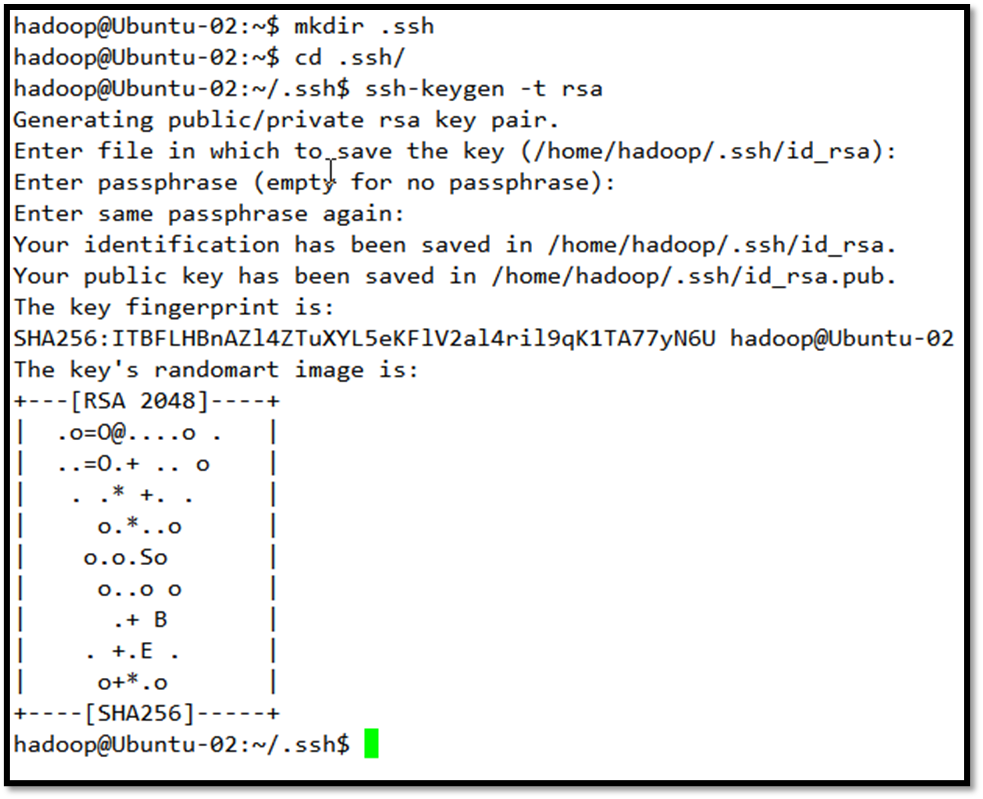
在个人目录/home/hadoop下新建.ssh文件夹,在.ssh中执行
ssh-keygen -t rsa
系统会问你一些配置,由于是初次实验,不需要这些内容,点回车继续下去即可。完成后会在.ssh/下生成id_rsa和id_rsa.pub两个文件,三台机器做同样处理。
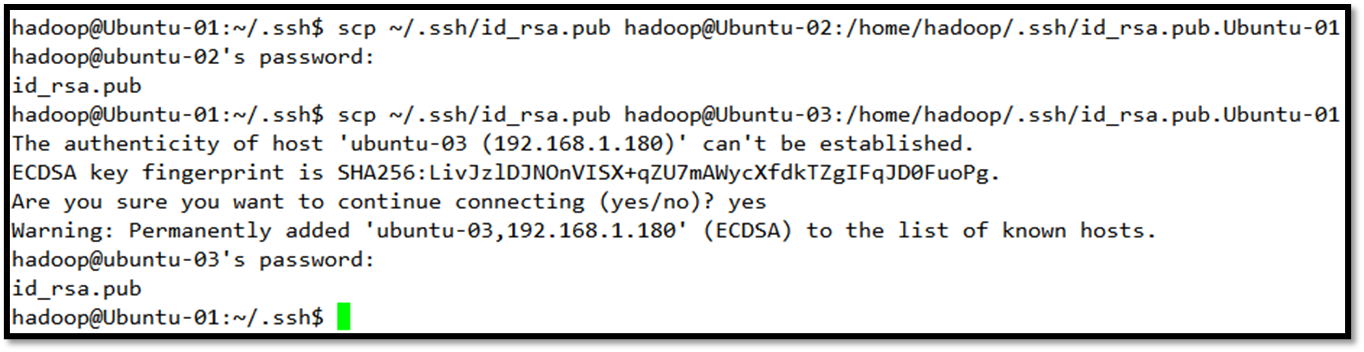
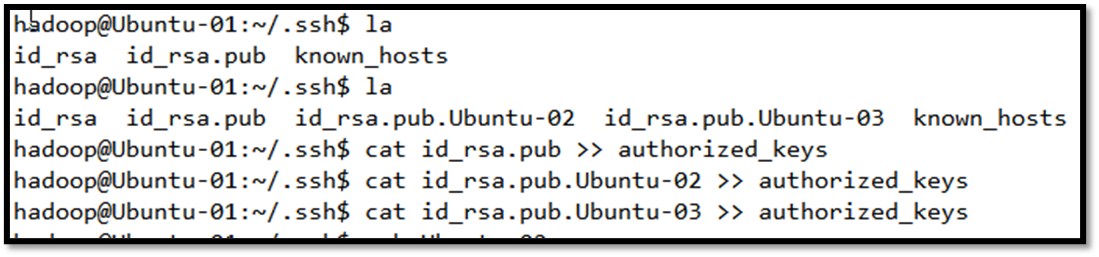
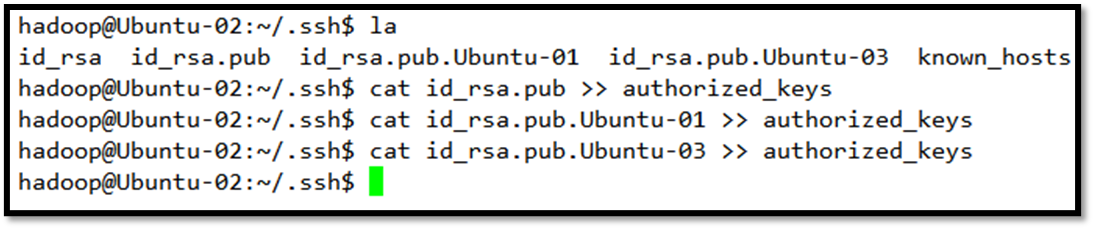
接下来把它们的密钥相互交换,这样做的目的是把Ubuntu-01的密钥交给Ubuntu-02和Ubuntu-03,对Ubuntu-02和Ubuntu-03做同样处理,完成后每一个机器的/.ssh/中应该有3个密钥,一个是自己的,另两个是别人的。
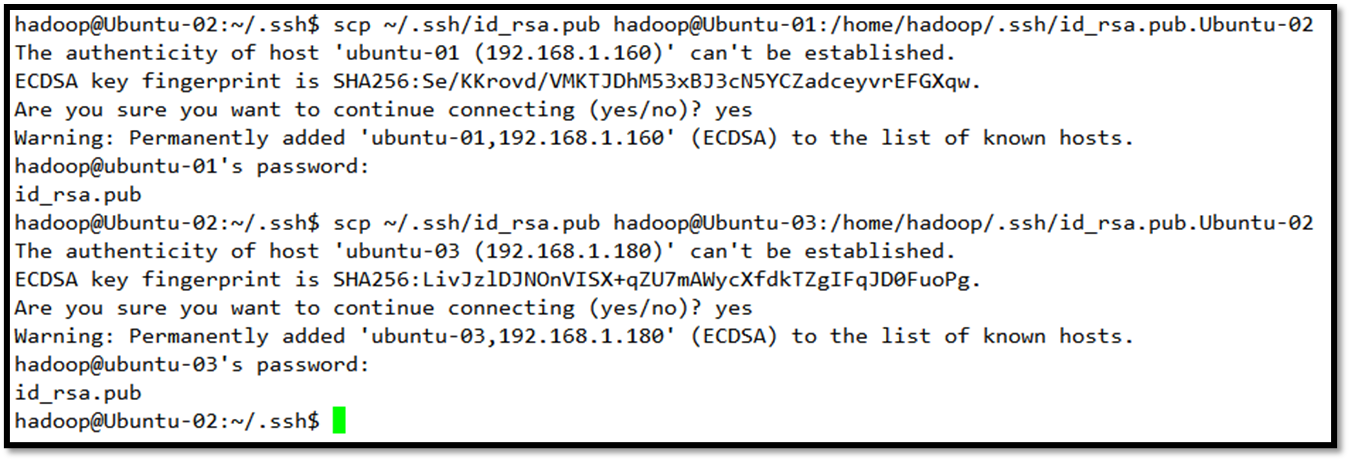
把自己的密钥连同别人的两个密钥加到授权密钥中

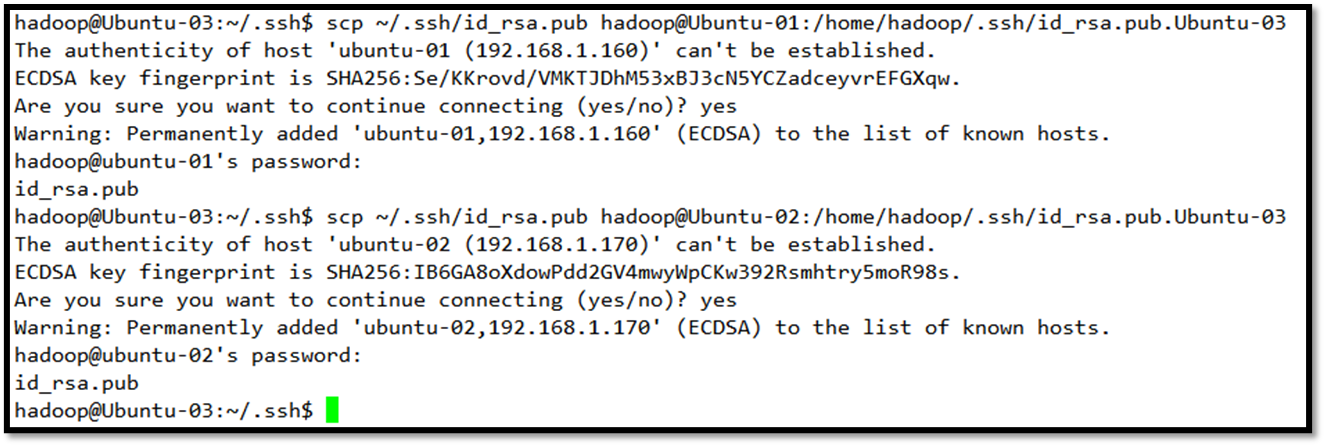
接下来检验相互之间是否可以通过ssh实现无密码访问
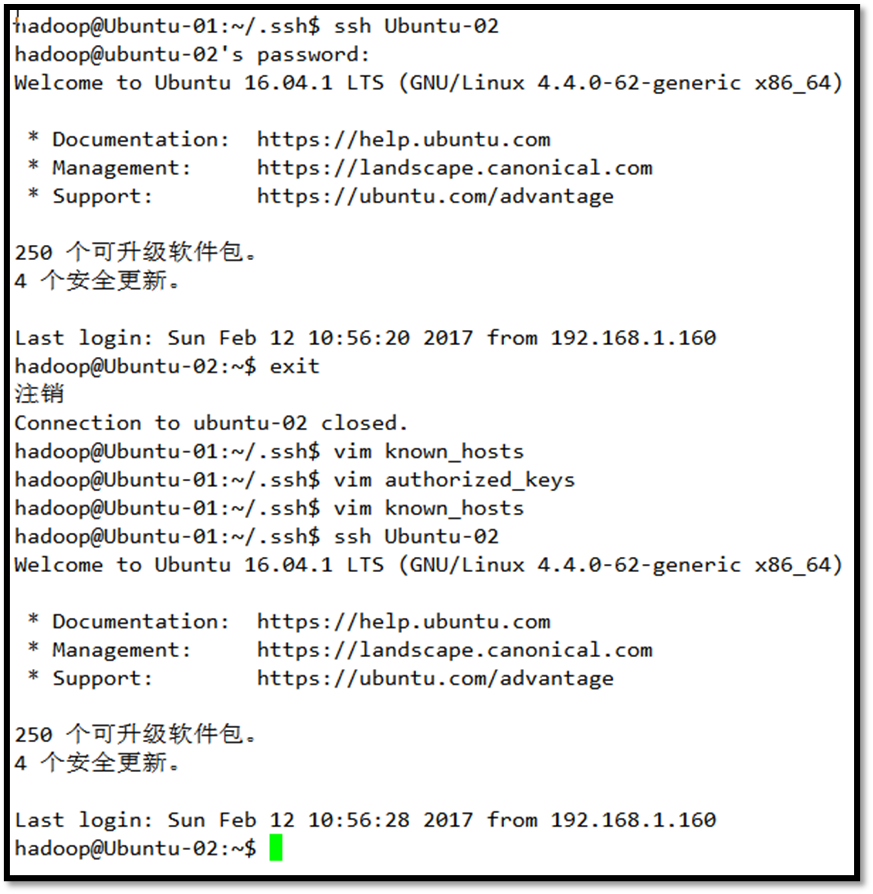
访问成功会显示欢迎信息,初次访问需要yes,之后就可以不直接访问了。
安装JDK
首先利用java -version命令,检查系统中有没有openjdk,如果有的话利用下面的命令删除:
sudo apt-get purge openjdk*
在此次安装的权限系统中没有发现openjdk。

此次安装的jdk版本为jdk-8u121-linux-x64。 下载地址为:http://www.oracle.com
hadoop@Ubuntu-01:~$ cd /usr/local
hadoop@Ubuntu-01:/usr/local$ sudo mkdir java
hadoop@Ubuntu-01:/usr/local$ sudo chown hadoop:hadoop java/
上传jdk-8u121-linux-x64.tar.gz到java目录
hadoop@Ubuntu-01:/usr/local$ cd java/
hadoop@Ubuntu-01:/usr/local/java$ tar -zxvf jdk-8u121-linux-x64.tar.gz

sudo vim /etc/profile
在文件末尾添加如下内容:
export JAVA_HOME=/usr/local/java/jdk1.8.0_121
export CLASSPATH=.:$JAVA_HOME/lib:$CLASSPATH
export PATH=$JAVA_HOME/bin:$PATH
然后检查是否安装成功:
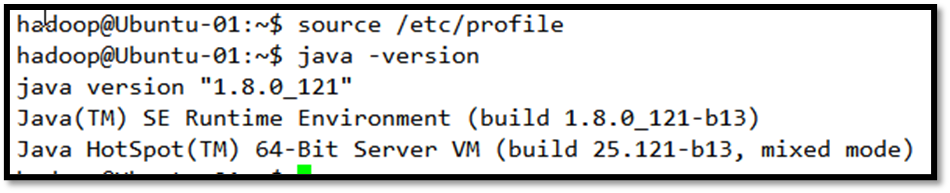
安装Hadoop
cd /usr/local
hadoop@Ubuntu-01:/usr/local$ sudo mkdir hadoop
hadoop@Ubuntu-01:/usr/local$ sudo chown hadoop:hadoop hadoop/
hadoop@Ubuntu-01:/usr/local$ cd hadoop/
hadoop@Ubuntu-01:/usr/local/hadoop$ tar -xzvf hadoop-2.7.3.tar.gz
hadoop@Ubuntu-01:/usr/local/hadoop$ rm hadoop-2.7.3.tar.gz
hadoop@Ubuntu-01:/usr/local/hadoop$ sudo vim /etc/profile
export HADOOP_HOME=/usr/local/hadoop/hadoop-2.7.3
export PATH=$HADOOP_HOME/bin:$HADOOP_HOME/sbin:$PATH
hadoop@Ubuntu-01:/usr/local/hadoop$ source /etc/profile
修改Hadoop配置文件
Hadoop配置文件均在/usr/local/hadoop/hadoop-2.7.3/etc/hadoop 下
hadoop-env.sh

虽然已经在/etc/profile中设置了JAVA_HOME环境变量,但是此处仍然要进行配置。
yarn-env.sh

由于已经设置了JAVA_HOME环境变量,此处可以不设置
slaves
core-site.xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://Ubuntu-01:9000</value>
</property>
<property>
<name>io.file.buffer.size</name>
<value>131072</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/hadoop-2.7.3/tmp</value>
<description>Abasefor other temporary directories.</description>
</property>
<property>
<name>hadoop.proxyuser.spark.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.spark.groups</name>
<value>*</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>Ubuntu-01:9001</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hadoop-2.7.3/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hadoop-2.7.3/tmp</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
</configuration>
mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>Ubuntu-01:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>Ubuntu-01:19888</value>
</property>
</configuration>
yarn-site.xml
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>Ubuntu-01:8032</value>
</property>
<property>
<name>yarn.resourcemanager.scheduler.address</name>
<value>Ubuntu-01:8030</value>
</property>
<property>
<name>yarn.resourcemanager.resource-tracker.address</name>
<value>Ubuntu-01:8035</value>
</property>
<property>
<name>yarn.resourcemanager.admin.address</name>
<value>Ubuntu-01:8033</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>Ubuntu-01:8088</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>192.168.0.160</value>
</property>
</configuration>
将配置好的hadoop文件copy到另一台slave机器上
hadoop@Ubuntu-01:/usr/local/hadoop$ scp -r hadoop-2.7.3/ hadoop@Ubuntu-02:/usr/local/hadoop/
hadoop@Ubuntu-01:/usr/local/hadoop$ scp -r hadoop-2.7.3/ hadoop@Ubuntu-03:/usr/local/hadoop/
验证
格式化namenode
hadoop@Ubuntu-01:/usr/local/hadoop/hadoop-2.7.3/etc/hadoop$ hdfs namenode -format
17/02/12 14:00:27 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = Ubuntu-01/127.0.1.1
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.7.3
STARTUP_MSG: classpath = /usr/local/hadoop/hadoop-2.7.3/etc/hadoop:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/jettison-1.1.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/gson-2.2.4.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/commons-digester-1.8.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/commons-configuration-1.6.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/jets3t-0.9.0.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/servlet-api-2.5.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/httpclient-4.2.5.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/hamcrest-core-1.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/jaxb-api-2.2.2.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/jersey-core-1.9.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/activation-1.1.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/apacheds-kerberos-codec-2.0.0-M15.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/commons-httpclient-3.1.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/jetty-6.1.26.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/java-xmlbuilder-0.4.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/hadoop-auth-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/commons-logging-1.1.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/commons-codec-1.4.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/jersey-server-1.9.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/jackson-core-asl-1.9.13.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/api-asn1-api-1.0.0-M20.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/curator-recipes-2.7.1.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/jsch-0.1.42.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/jackson-mapper-asl-1.9.13.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/api-util-1.0.0-M20.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/apacheds-i18n-2.0.0-M15.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/mockito-all-1.8.5.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/log4j-1.2.17.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/slf4j-api-1.7.10.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/jaxb-impl-2.2.3-1.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/netty-3.6.2.Final.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/commons-collections-3.2.2.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/stax-api-1.0-2.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/jsr305-3.0.0.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/httpcore-4.2.5.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/commons-math3-3.1.1.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/jackson-xc-1.9.13.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/htrace-core-3.1.0-incubating.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/commons-io-2.4.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/commons-net-3.1.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/snappy-java-1.0.4.1.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/curator-framework-2.7.1.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/commons-lang-2.6.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/junit-4.11.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/xz-1.0.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/guava-11.0.2.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/commons-beanutils-1.7.0.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/asm-3.2.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/avro-1.7.4.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/jersey-json-1.9.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/jetty-util-6.1.26.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/zookeeper-3.4.6.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/xmlenc-0.52.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/commons-beanutils-core-1.8.0.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/commons-compress-1.4.1.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/jackson-jaxrs-1.9.13.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/paranamer-2.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/commons-cli-1.2.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/protobuf-java-2.5.0.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/jsp-api-2.1.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/curator-client-2.7.1.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/hadoop-annotations-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/hadoop-common-2.7.3-tests.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/hadoop-nfs-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/hadoop-common-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/xml-apis-1.3.04.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/servlet-api-2.5.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/jersey-core-1.9.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/jetty-6.1.26.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/commons-logging-1.1.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/commons-codec-1.4.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/jersey-server-1.9.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/jackson-core-asl-1.9.13.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/netty-all-4.0.23.Final.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/jackson-mapper-asl-1.9.13.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/log4j-1.2.17.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/netty-3.6.2.Final.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/jsr305-3.0.0.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/htrace-core-3.1.0-incubating.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/commons-io-2.4.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/commons-lang-2.6.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/xercesImpl-2.9.1.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/guava-11.0.2.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/asm-3.2.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/commons-daemon-1.0.13.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/jetty-util-6.1.26.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/xmlenc-0.52.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/leveldbjni-all-1.8.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/commons-cli-1.2.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/lib/protobuf-java-2.5.0.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/hadoop-hdfs-nfs-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/hadoop-hdfs-2.7.3-tests.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/hdfs/hadoop-hdfs-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/jettison-1.1.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/servlet-api-2.5.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/guice-3.0.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/aopalliance-1.0.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/jaxb-api-2.2.2.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/guice-servlet-3.0.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/jersey-core-1.9.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/activation-1.1.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/jetty-6.1.26.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/commons-logging-1.1.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/commons-codec-1.4.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/jersey-server-1.9.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/jackson-core-asl-1.9.13.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/jackson-mapper-asl-1.9.13.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/log4j-1.2.17.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/jaxb-impl-2.2.3-1.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/netty-3.6.2.Final.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/commons-collections-3.2.2.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/stax-api-1.0-2.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/jsr305-3.0.0.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/jackson-xc-1.9.13.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/commons-io-2.4.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/commons-lang-2.6.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/jersey-guice-1.9.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/xz-1.0.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/guava-11.0.2.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/asm-3.2.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/jersey-json-1.9.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/jetty-util-6.1.26.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/zookeeper-3.4.6.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/jersey-client-1.9.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/commons-compress-1.4.1.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/jackson-jaxrs-1.9.13.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/leveldbjni-all-1.8.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/zookeeper-3.4.6-tests.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/commons-cli-1.2.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/protobuf-java-2.5.0.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/lib/javax.inject-1.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-registry-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-sharedcachemanager-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-resourcemanager-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-web-proxy-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-client-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-nodemanager-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-api-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-tests-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-common-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-applications-distributedshell-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-common-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-server-applicationhistoryservice-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/yarn/hadoop-yarn-applications-unmanaged-am-launcher-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/lib/hamcrest-core-1.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/lib/guice-3.0.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/lib/aopalliance-1.0.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/lib/guice-servlet-3.0.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/lib/jersey-core-1.9.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/lib/jersey-server-1.9.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/lib/jackson-core-asl-1.9.13.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/lib/jackson-mapper-asl-1.9.13.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/lib/log4j-1.2.17.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/lib/netty-3.6.2.Final.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/lib/commons-io-2.4.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/lib/snappy-java-1.0.4.1.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/lib/junit-4.11.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/lib/jersey-guice-1.9.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/lib/xz-1.0.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/lib/asm-3.2.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/lib/avro-1.7.4.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/lib/commons-compress-1.4.1.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/lib/paranamer-2.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/lib/leveldbjni-all-1.8.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/lib/protobuf-java-2.5.0.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/lib/javax.inject-1.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/lib/hadoop-annotations-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-client-app-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-client-hs-plugins-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-client-common-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-client-core-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-client-shuffle-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-client-jobclient-2.7.3-tests.jar:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar:/usr/local/hadoop/hadoop-2.7.3/contrib/capacity-scheduler/*.jar
STARTUP_MSG: build = https://git-wip-us.apache.org/repos/asf/hadoop.git -r baa91f7c6bc9cb92be5982de4719c1c8af91ccff; compiled by 'root' on 2016-08-18T01:41Z
STARTUP_MSG: java = 1.8.0_121
************************************************************/
17/02/12 14:00:27 INFO namenode.NameNode: registered UNIX signal handlers for [TERM, HUP, INT]
17/02/12 14:00:27 INFO namenode.NameNode: createNameNode [-format]
Formatting using clusterid: CID-7e34c743-19b0-4ebb-b922-37e8657a8090
17/02/12 14:00:27 INFO namenode.FSNamesystem: No KeyProvider found.
17/02/12 14:00:27 INFO namenode.FSNamesystem: fsLock is fair:true
17/02/12 14:00:27 INFO blockmanagement.DatanodeManager: dfs.block.invalidate.limit=1000
17/02/12 14:00:27 INFO blockmanagement.DatanodeManager: dfs.namenode.datanode.registration.ip-hostname-check=true
17/02/12 14:00:27 INFO blockmanagement.BlockManager: dfs.namenode.startup.delay.block.deletion.sec is set to 000:00:00:00.000
17/02/12 14:00:27 INFO blockmanagement.BlockManager: The block deletion will start around 2017 二月 12 14:00:27
17/02/12 14:00:27 INFO util.GSet: Computing capacity for map BlocksMap
17/02/12 14:00:27 INFO util.GSet: VM type = 64-bit
17/02/12 14:00:28 INFO util.GSet: 2.0% max memory 966.7 MB = 19.3 MB
17/02/12 14:00:28 INFO util.GSet: capacity = 2^21 = 2097152 entries
17/02/12 14:00:28 INFO blockmanagement.BlockManager: dfs.block.access.token.enable=false
17/02/12 14:00:28 INFO blockmanagement.BlockManager: defaultReplication = 3
17/02/12 14:00:28 INFO blockmanagement.BlockManager: maxReplication = 512
17/02/12 14:00:28 INFO blockmanagement.BlockManager: minReplication = 1
17/02/12 14:00:28 INFO blockmanagement.BlockManager: maxReplicationStreams = 2
17/02/12 14:00:28 INFO blockmanagement.BlockManager: replicationRecheckInterval = 3000
17/02/12 14:00:28 INFO blockmanagement.BlockManager: encryptDataTransfer = false
17/02/12 14:00:28 INFO blockmanagement.BlockManager: maxNumBlocksToLog = 1000
17/02/12 14:00:28 INFO namenode.FSNamesystem: fsOwner = hadoop (auth:SIMPLE)
17/02/12 14:00:28 INFO namenode.FSNamesystem: supergroup = supergroup
17/02/12 14:00:28 INFO namenode.FSNamesystem: isPermissionEnabled = true
17/02/12 14:00:28 INFO namenode.FSNamesystem: HA Enabled: false
17/02/12 14:00:28 INFO namenode.FSNamesystem: Append Enabled: true
17/02/12 14:00:28 INFO util.GSet: Computing capacity for map INodeMap
17/02/12 14:00:28 INFO util.GSet: VM type = 64-bit
17/02/12 14:00:28 INFO util.GSet: 1.0% max memory 966.7 MB = 9.7 MB
17/02/12 14:00:28 INFO util.GSet: capacity = 2^20 = 1048576 entries
17/02/12 14:00:28 INFO namenode.FSDirectory: ACLs enabled? false
17/02/12 14:00:28 INFO namenode.FSDirectory: XAttrs enabled? true
17/02/12 14:00:28 INFO namenode.FSDirectory: Maximum size of an xattr: 16384
17/02/12 14:00:28 INFO namenode.NameNode: Caching file names occuring more than 10 times
17/02/12 14:00:28 INFO util.GSet: Computing capacity for map cachedBlocks
17/02/12 14:00:28 INFO util.GSet: VM type = 64-bit
17/02/12 14:00:28 INFO util.GSet: 0.25% max memory 966.7 MB = 2.4 MB
17/02/12 14:00:28 INFO util.GSet: capacity = 2^18 = 262144 entries
17/02/12 14:00:28 INFO namenode.FSNamesystem: dfs.namenode.safemode.threshold-pct = 0.9990000128746033
17/02/12 14:00:28 INFO namenode.FSNamesystem: dfs.namenode.safemode.min.datanodes = 0
17/02/12 14:00:28 INFO namenode.FSNamesystem: dfs.namenode.safemode.extension = 30000
17/02/12 14:00:28 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.window.num.buckets = 10
17/02/12 14:00:28 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.num.users = 10
17/02/12 14:00:28 INFO metrics.TopMetrics: NNTop conf: dfs.namenode.top.windows.minutes = 1,5,25
17/02/12 14:00:28 INFO namenode.FSNamesystem: Retry cache on namenode is enabled
17/02/12 14:00:28 INFO namenode.FSNamesystem: Retry cache will use 0.03 of total heap and retry cache entry expiry time is 600000 millis
17/02/12 14:00:28 INFO util.GSet: Computing capacity for map NameNodeRetryCache
17/02/12 14:00:28 INFO util.GSet: VM type = 64-bit
17/02/12 14:00:28 INFO util.GSet: 0.029999999329447746% max memory 966.7 MB = 297.0 KB
17/02/12 14:00:28 INFO util.GSet: capacity = 2^15 = 32768 entries
Re-format filesystem in Storage Directory /usr/local/hadoop/hadoop-2.7.3/name ? (Y or N) Y
17/02/12 14:00:33 INFO namenode.FSImage: Allocated new BlockPoolId: BP-1871053033-127.0.1.1-1486879233735
17/02/12 14:00:33 INFO common.Storage: Storage directory /usr/local/hadoop/hadoop-2.7.3/name has been successfully formatted.
17/02/12 14:00:33 INFO namenode.FSImageFormatProtobuf: Saving image file /usr/local/hadoop/hadoop-2.7.3/name/current/fsimage.ckpt_0000000000000000000 using no compression
17/02/12 14:00:33 INFO namenode.FSImageFormatProtobuf: Image file /usr/local/hadoop/hadoop-2.7.3/name/current/fsimage.ckpt_0000000000000000000 of size 353 bytes saved in 0 seconds.
17/02/12 14:00:33 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
17/02/12 14:00:33 INFO util.ExitUtil: Exiting with status 0
17/02/12 14:00:33 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at Ubuntu-01/127.0.1.1
************************************************************/
启动hdfs
hadoop@Ubuntu-01:/usr/local/hadoop/hadoop-2.7.3/etc/hadoop$ start-dfs.sh
Starting namenodes on [Ubuntu-01]
Ubuntu-01: starting namenode, logging to /usr/local/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-namenode-Ubuntu-01.out
Ubuntu-03: starting datanode, logging to /usr/local/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-Ubuntu-03.out
Ubuntu-02: starting datanode, logging to /usr/local/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-Ubuntu-02.out
Starting secondary namenodes [Ubuntu-01]
Ubuntu-01: starting secondarynamenode, logging to /usr/local/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-secondarynamenode-Ubuntu-01.out
hadoop@Ubuntu-01:/usr/local/hadoop/hadoop-2.7.3/etc/hadoop$ jps
9466 Jps
9147 NameNode
9357 SecondaryNameNode
停止hdfs
hadoop@Ubuntu-01:/usr/local/hadoop/hadoop-2.7.3/etc/hadoop$ stop-dfs.sh
Stopping namenodes on [Ubuntu-01]
Ubuntu-01: stopping namenode
Ubuntu-02: stopping datanode
Ubuntu-03: stopping datanode
Stopping secondary namenodes [Ubuntu-01]
Ubuntu-01: stopping secondarynamenode
hadoop@Ubuntu-01:/usr/local/hadoop/hadoop-2.7.3/etc/hadoop$ jps
9814 Jps
启动yarn
hadoop@Ubuntu-01:~$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/hadoop-2.7.3/logs/yarn-hadoop-resourcemanager-Ubuntu-01.out
Ubuntu-02: starting nodemanager, logging to /usr/local/hadoop/hadoop-2.7.3/logs/yarn-hadoop-nodemanager-Ubuntu-02.out
Ubuntu-03: starting nodemanager, logging to /usr/local/hadoop/hadoop-2.7.3/logs/yarn-hadoop-nodemanager-Ubuntu-03.out
hadoop@Ubuntu-01:~$ jps
6252 ResourceManager
6509 Jps
停止yarn
hadoop@Ubuntu-01:~$ stop-yarn.sh
stopping yarn daemons
stopping resourcemanager
Ubuntu-03: stopping nodemanager
Ubuntu-02: stopping nodemanager
Ubuntu-03: nodemanager did not stop gracefully after 5 seconds: killing with kill -9
Ubuntu-02: nodemanager did not stop gracefully after 5 seconds: killing with kill -9
no proxyserver to stop
查看集群状态
hadoop@Ubuntu-01:/usr/local/hadoop/hadoop-2.7.3/etc/hadoop$ hdfs dfsadmin -report
report: Call From Ubuntu-01/127.0.1.1 to Ubuntu-01:9000 failed on connection exception: java.net.ConnectException: 拒绝连接; For more details see: http://wiki.apache.org/hadoop/ConnectionRefused
hadoop@Ubuntu-01:/usr/local/hadoop/hadoop-2.7.3/etc/hadoop$ start-dfs.sh
Starting namenodes on [Ubuntu-01]
Ubuntu-01: starting namenode, logging to /usr/local/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-namenode-Ubuntu-01.out
Ubuntu-03: starting datanode, logging to /usr/local/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-Ubuntu-03.out
Ubuntu-02: starting datanode, logging to /usr/local/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-Ubuntu-02.out
Starting secondary namenodes [Ubuntu-01]
Ubuntu-01: starting secondarynamenode, logging to /usr/local/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-secondarynamenode-Ubuntu-01.out
hadoop@Ubuntu-01:~$ hdfs dfsadmin -report
Configured Capacity: 82167201792 (76.52 GB)
Present Capacity: 67444781056 (62.81 GB)
DFS Remaining: 67444297728 (62.81 GB)
DFS Used: 483328 (472 KB)
DFS Used%: 0.00%
Under replicated blocks: 0
Blocks with corrupt replicas: 0
Missing blocks: 0
Missing blocks (with replication factor 1): 0
-------------------------------------------------
Live datanodes (2):
Name: 192.168.1.180:50010 (Ubuntu-03)
Hostname: Ubuntu-03
Decommission Status : Normal
Configured Capacity: 41083600896 (38.26 GB)
DFS Used: 241664 (236 KB)
Non DFS Used: 7351656448 (6.85 GB)
DFS Remaining: 33731702784 (31.42 GB)
DFS Used%: 0.00%
DFS Remaining%: 82.11%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Sun Feb 12 23:18:24 CST 2017
Name: 192.168.1.170:50010 (Ubuntu-02)
Hostname: Ubuntu-02
Decommission Status : Normal
Configured Capacity: 41083600896 (38.26 GB)
DFS Used: 241664 (236 KB)
Non DFS Used: 7370764288 (6.86 GB)
DFS Remaining: 33712594944 (31.40 GB)
DFS Used%: 0.00%
DFS Remaining%: 82.06%
Configured Cache Capacity: 0 (0 B)
Cache Used: 0 (0 B)
Cache Remaining: 0 (0 B)
Cache Used%: 100.00%
Cache Remaining%: 0.00%
Xceivers: 1
Last contact: Sun Feb 12 23:18:24 CST 2017
查看HDFS前台
http://192.168.1.160:50070/
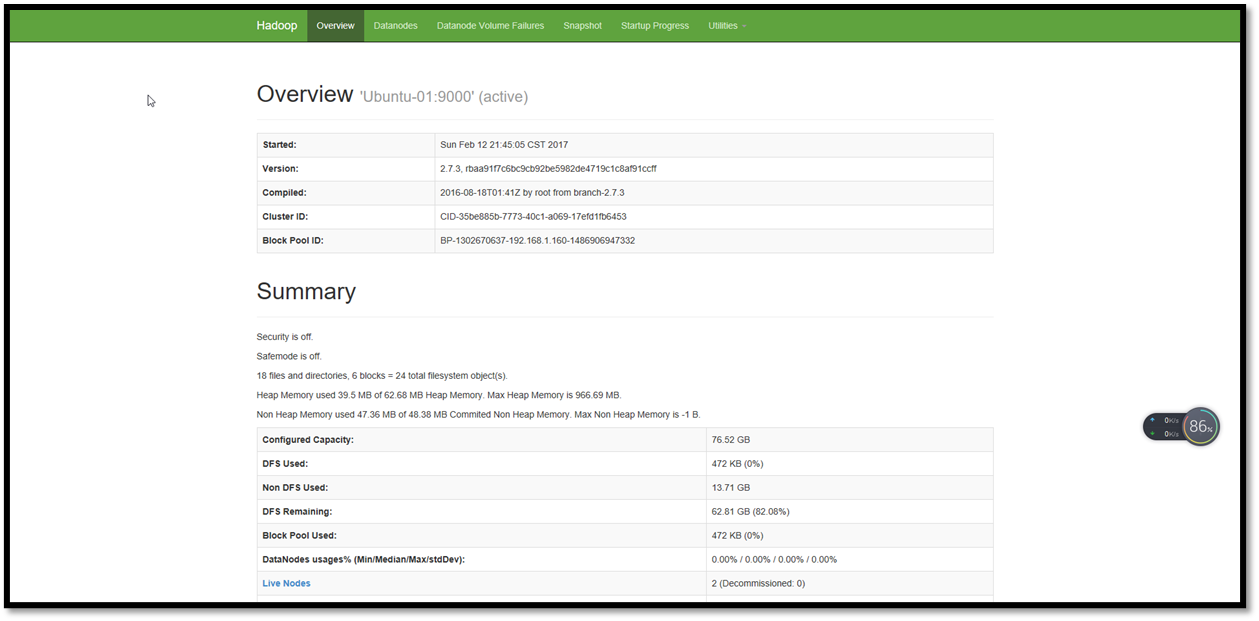
查看RM
http://192.168.1.160:8088/

查看Jobhistory
hadoop@Ubuntu-01:~$ mr-jobhistory-daemon.sh start historyserver
starting historyserver, logging to /usr/local/hadoop/hadoop-2.7.3/logs/mapred-hadoop-historyserver-Ubuntu-01.out
hadoop@Ubuntu-01:~$ mr-jobhistory-daemon.sh stop historyserver
stopping historyserver
http://192.168.1.160:19888/jobhistory
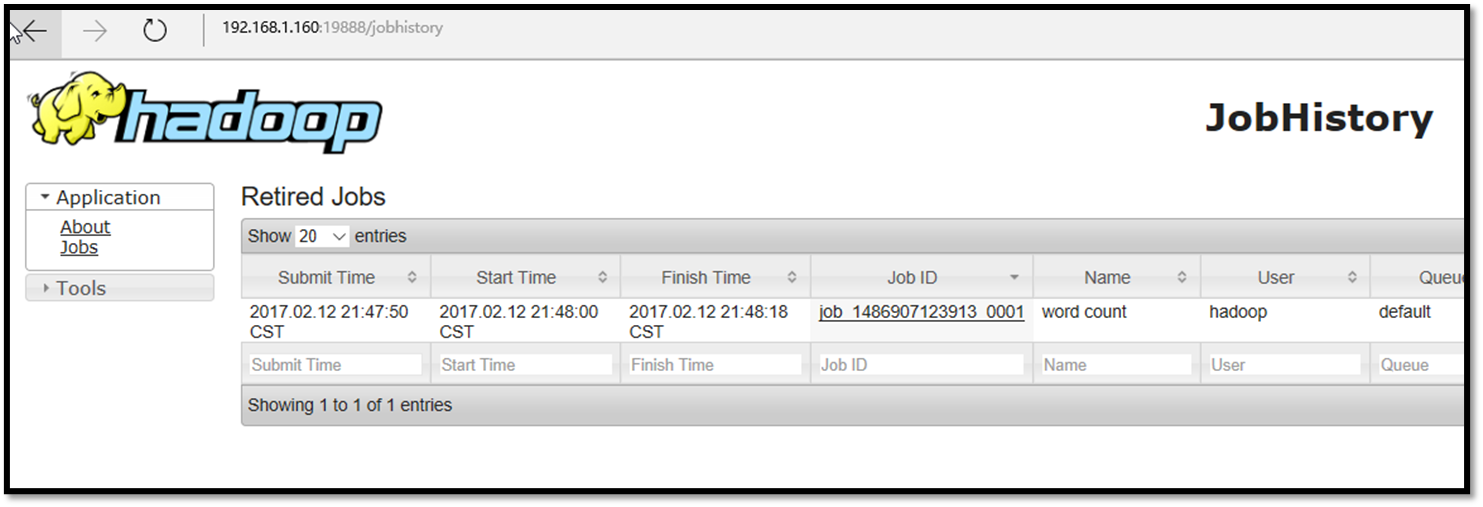
运行wordcount程序
创建 input目录
hadoop@Ubuntu-01:~$ mkdir input
在input创建f1、f2并写内容
hadoop@Ubuntu-01:~$ cat input/f1
Hello world bye jj
hadoop@Ubuntu-01:~$ cat input/f2
Hello Hadoop bye Hadoop
在hdfs创建/tmp/input目录
hadoop@Ubuntu-01:~$ hadoop fs -mkdir /tmp
hadoop@Ubuntu-01:~$ hadoop fs -mkdir /tmp/input
将f1、f2文件copy到hdfs /tmp/input目录
hadoop@Ubuntu-01:~$ hadoop fs -put input/ /tmp
执行wordcount程序
hadoop@Ubuntu-01:~$ hadoop jar /usr/local/hadoop/hadoop-2.7.3/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.3.jar wordcount /tmp/input /output
17/02/12 21:47:48 INFO client.RMProxy: Connecting to ResourceManager at Ubuntu-01/192.168.1.160:8032
17/02/12 21:47:49 INFO input.FileInputFormat: Total input paths to process : 2
17/02/12 21:47:49 INFO mapreduce.JobSubmitter: number of splits:2
17/02/12 21:47:50 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1486907123913_0001
17/02/12 21:47:50 INFO impl.YarnClientImpl: Submitted application application_1486907123913_0001
17/02/12 21:47:50 INFO mapreduce.Job: The url to track the job: http://Ubuntu-01:8088/proxy/application_1486907123913_0001/
17/02/12 21:47:50 INFO mapreduce.Job: Running job: job_1486907123913_0001
17/02/12 21:48:02 INFO mapreduce.Job: Job job_1486907123913_0001 running in uber mode : false
17/02/12 21:48:02 INFO mapreduce.Job: map 0% reduce 0%
17/02/12 21:48:12 INFO mapreduce.Job: map 100% reduce 0%
17/02/12 21:48:20 INFO mapreduce.Job: map 100% reduce 100%
17/02/12 21:48:21 INFO mapreduce.Job: Job job_1486907123913_0001 completed successfully
17/02/12 21:48:21 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=84
FILE: Number of bytes written=357236
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=243
HDFS: Number of bytes written=36
HDFS: Number of read operations=9
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=2
Launched reduce tasks=1
Data-local map tasks=2
Total time spent by all maps in occupied slots (ms)=16865
Total time spent by all reduces in occupied slots (ms)=4585
Total time spent by all map tasks (ms)=16865
Total time spent by all reduce tasks (ms)=4585
Total vcore-milliseconds taken by all map tasks=16865
Total vcore-milliseconds taken by all reduce tasks=4585
Total megabyte-milliseconds taken by all map tasks=17269760
Total megabyte-milliseconds taken by all reduce tasks=4695040
Map-Reduce Framework
Map input records=2
Map output records=8
Map output bytes=75
Map output materialized bytes=90
Input split bytes=198
Combine input records=8
Combine output records=7
Reduce input groups=5
Reduce shuffle bytes=90
Reduce input records=7
Reduce output records=5
Spilled Records=14
Shuffled Maps =2
Failed Shuffles=0
Merged Map outputs=2
GC time elapsed (ms)=426
CPU time spent (ms)=1580
Physical memory (bytes) snapshot=508022784
Virtual memory (bytes) snapshot=5689307136
Total committed heap usage (bytes)=263376896
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=45
File Output Format Counters
Bytes Written=36
查看执行结果
hadoop@Ubuntu-01:~$ hadoop fs -cat /output/part-r-00000
Hadoop 2
Hello 2
bye 2
jj 1
world 1
安装Scala
scala-2.11.8.tgz http://www.scala-lang.org/download/
hadoop@Ubuntu-01:~$ cd /usr/local
hadoop@Ubuntu-01:/usr/local$ sudo mkdir scala
hadoop@Ubuntu-01:/usr/local$ sudo chown hadoop:hadoop scala
hadoop@Ubuntu-01:/usr/local$ cd scala/
hadoop@Ubuntu-01:/usr/local/scala$ tar -zxvf scala-2.11.8.tgz
hadoop@Ubuntu-01:/usr/local/scala$ sudo vim /etc/profile
末尾加入:
export SCALA_HOME=/usr/local/scala/scala-2.11.8
export PATH=$PATH:$SCALA_HOME/bin
hadoop@Ubuntu-01:/usr/local/scala$ source /etc/profile

另外两台机器进行类似操作安装scala
安装Spark
http://spark.apache.org/
spark-2.1.0-bin-hadoop2.7.tgz
hadoop@Ubuntu-01:~$ cd /usr/local
hadoop@Ubuntu-01:/usr/local$ sudo mkdir spark
hadoop@Ubuntu-01:/usr/local$ sudo chown hadoop:hadoop spark
hadoop@Ubuntu-01:/usr/local$ cd spark/
hadoop@Ubuntu-01:/usr/local/spark$ tar -zxvf spark-2.1.0-bin-hadoop2.7.tgz
hadoop@Ubuntu-01:/usr/local/spark$ sudo vim /etc/profile
export SPARK_HOME=/usr/local/spark/spark-2.1.0-bin-hadoop2.7
export PATH=$PATH:$SPARK_HOME/bin:$SPARK_HOME/sbin
hadoop@Ubuntu-01:/usr/local/spark$ source /etc/profile
另外两台进行类似操作
配置
cd /usr/local/spark/conf
mv spark-env.sh.template spark-env.sh
vim spark-env.sh
HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
SPARK_MASTER_HOST=192.168.1.160
SPARK_MASTER_WEBUI_PORT=28686
SPARK_LOCAL_DIRS=/usr/local/spark/spark-2.1.0-bin-hadoop2.7/tmp/local
SPARK_WORKER_DIR=/usr/local/spark/spark-2.1.0-bin-hadoop2.7/tmp/worker
SPARK_DRIVER_MEMORY=4G
SPARK_WORKER_CORES=16
SPARK_WORKER_MEMORY=64g
SPARK_LOG_DIR=/usr/local/spark/spark-2.1.0-bin-hadoop2.7/tmp/logs
# 下面的配置主要用于jobhistory,非必须
SPARK_HISTORY_OPTS="-Dspark.history.ui.port=18080 -Dspark.history.retainedApplications=3 -Dspark.history.fs.logDirectory=hdfs://Ubuntu-01:9000/spark/log"
mv spark-defaults.conf.template spark-defaults.conf
vim spark-defaults.conf
#下面的配置主要用于jobhistory,非必须
spark.eventLog.enabled true
spark.eventLog.dir hdfs://Ubuntu-01:9000/spark/log
spark.eventLog.compress true
复制spark目录
hadoop@Ubuntu-01:/usr/local/spark$ scp -r spark-2.1.0-bin-hadoop2.7/ hadoop@Ubuntu-02:/usr/local/spark
hadoop@Ubuntu-01:/usr/local/spark$ scp -r spark-2.1.0-bin-hadoop2.7/ hadoop@Ubuntu-03:/usr/local/spark
验证
hadoop@Ubuntu-01:~$ start-dfs.sh
Starting namenodes on [Ubuntu-01]
Ubuntu-01: starting namenode, logging to /usr/local/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-namenode-Ubuntu-01.out
Ubuntu-02: starting datanode, logging to /usr/local/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-Ubuntu-02.out
Ubuntu-03: starting datanode, logging to /usr/local/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-Ubuntu-03.out
Starting secondary namenodes [Ubuntu-01]
Ubuntu-01: starting secondarynamenode, logging to /usr/local/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-secondarynamenode-Ubuntu-01.out
hadoop@Ubuntu-01:~$ jps
5057 SecondaryNameNode
4846 NameNode
5166 Jps
hadoop@Ubuntu-01:~$ start-yarn.sh
starting yarn daemons
starting resourcemanager, logging to /usr/local/hadoop/hadoop-2.7.3/logs/yarn-hadoop-resourcemanager-Ubuntu-01.out
Ubuntu-02: starting nodemanager, logging to /usr/local/hadoop/hadoop-2.7.3/logs/yarn-hadoop-nodemanager-Ubuntu-02.out
Ubuntu-03: starting nodemanager, logging to /usr/local/hadoop/hadoop-2.7.3/logs/yarn-hadoop-nodemanager-Ubuntu-03.out
hadoop@Ubuntu-01:~$ jps
5568 Jps
5057 SecondaryNameNode
5223 ResourceManager
4846 NameNode
hadoop@Ubuntu-01:~$ start-master.sh
starting org.apache.spark.deploy.master.Master, logging to /usr/local/spark/spark-2.1.0-bin-hadoop2.7/tmp/logs/spark-hadoop-org.apache.spark.deploy.master.Master-1-Ubuntu-01.out
hadoop@Ubuntu-01:~$ jps
5649 Jps
5057 SecondaryNameNode
5223 ResourceManager
5597 Master
4846 NameNode
hadoop@Ubuntu-01:~$ start-slave.sh 192.168.1.160:7077
starting org.apache.spark.deploy.worker.Worker, logging to /usr/local/spark/spark-2.1.0-bin-hadoop2.7/tmp/logs/spark-hadoop-org.apache.spark.deploy.worker.Worker-1-Ubuntu-01.out
hadoop@Ubuntu-01:~$ jps
5057 SecondaryNameNode
5223 ResourceManager
5672 Worker
5720 Jps
5597 Master
4846 NameNode
hadoop@Ubuntu-01:~$ start-history-server.sh
starting org.apache.spark.deploy.history.HistoryServer, logging to /usr/local/spark/spark-2.1.0-bin-hadoop2.7/tmp/logs/spark-hadoop-org.apache.spark.deploy.history.HistoryServer-1-Ubuntu-01.out
hadoop@Ubuntu-01:~$ run-example org.apache.spark.examples.SparkPi 2>%1 | grep "Pi is roughly"
Pi is roughly 3.140195700978505
hadoop@Ubuntu-01:~$ spark-submit $SPARK_HOME/examples/src/main/python/pi.py 2>%1 | grep "Pi is roughly"
Pi is roughly 3.146920
hadoop@Ubuntu-01:~$ spark-shell
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
17/02/15 22:30:19 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
17/02/15 22:30:29 WARN metastore.ObjectStore: Version information not found in metastore. hive.metastore.schema.verification is not enabled so recording the schema version 1.2.0
17/02/15 22:30:29 WARN metastore.ObjectStore: Failed to get database default, returning NoSuchObjectException
17/02/15 22:30:32 WARN metastore.ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
Spark context Web UI available at http://192.168.1.160:4040
Spark context available as 'sc' (master = local[*], app id = local-1487169020439).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.1.0
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_121)
Type in expressions to have them evaluated.
Type :help for more information.
scala> val textFile =sc.textFile("file:///usr/local/spark/spark-2.1.0-bin-hadoop2.7/README.md");
textFile: org.apache.spark.rdd.RDD[String] = file:///usr/local/spark/spark-2.1.0-bin-hadoop2.7/README.md MapPartitionsRDD[1] at textFile at <console>:24
scala> textFile.count();
res8: Long = 104
scala> textFile.first();
res9: String = # Apache Spark
scala> val linesWithSpark = textFile.filter(line=> line.contains("Spark"));
linesWithSpark: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[2] at filter at <console>:26
scala> linesWithSpark.count();
res10: Long = 20
scala> textFile.filter(line =>line.contains("Spark")).count();
res11: Long = 20
scala>
前台界面
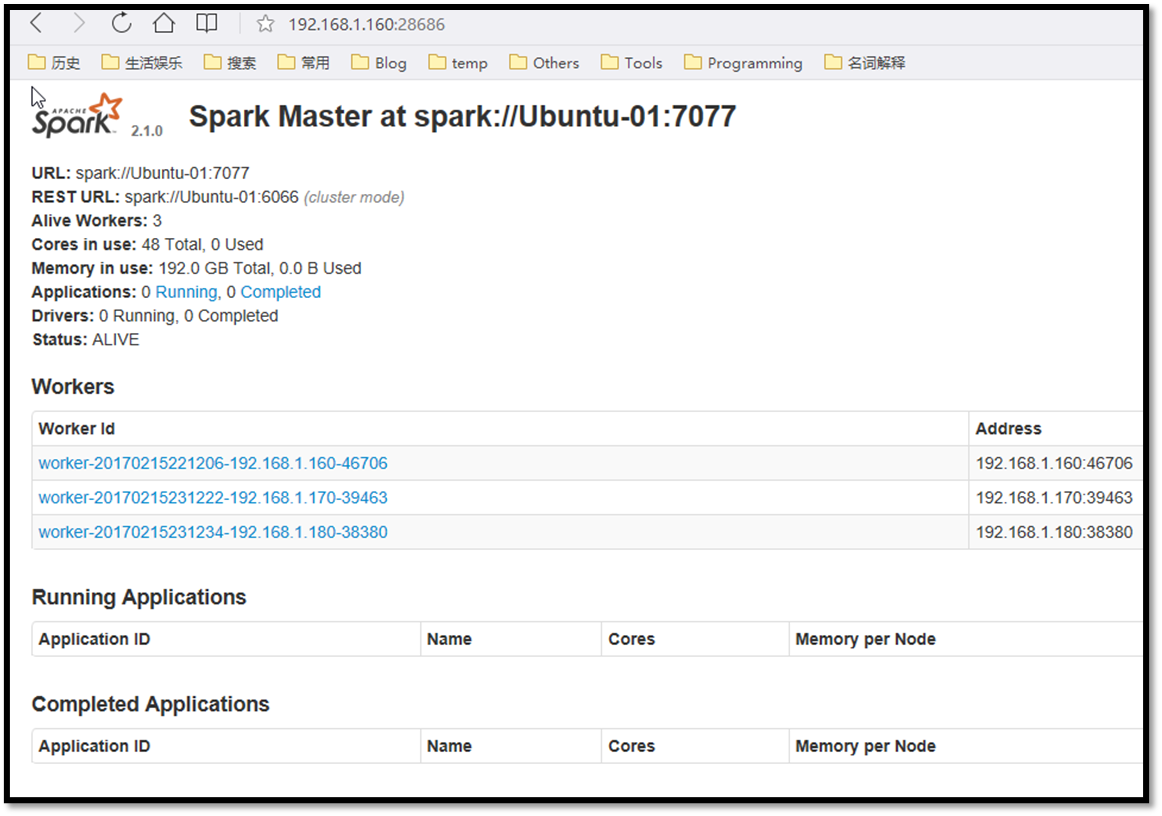
SPARK_MASTER_WEBUI: http://192.168.1.160:28686/
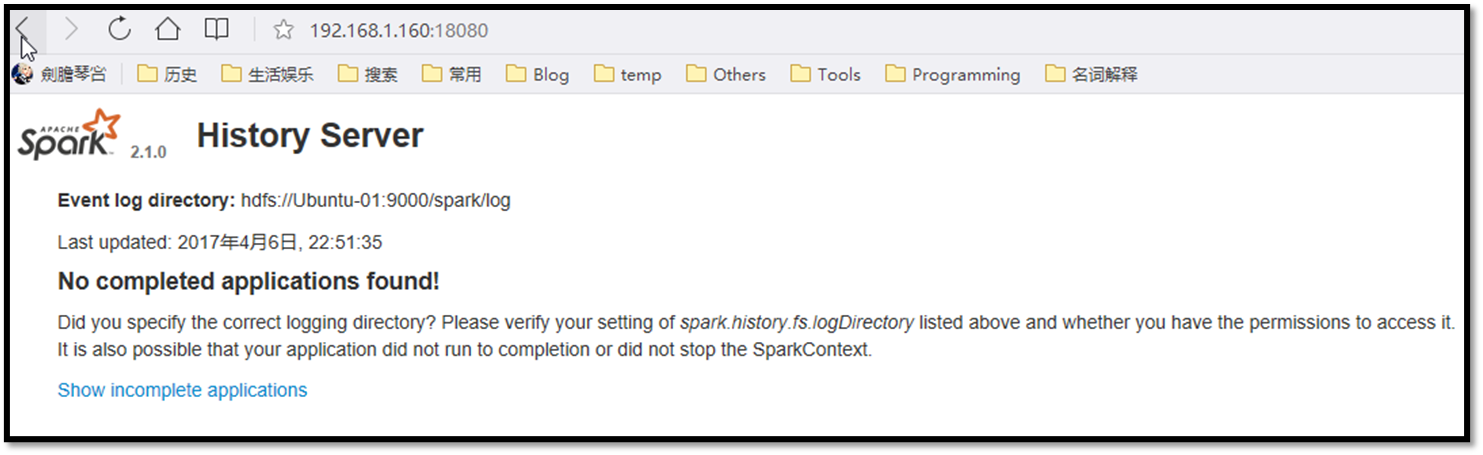
SPARK_HISTORY:http://192.168.1.160:18080/
关闭顺序
hadoop@Ubuntu-01:~$ stop-history-server.sh
stopping org.apache.spark.deploy.history.HistoryServer
hadoop@Ubuntu-01:~$ stop-slaves.sh
Ubuntu-02: stopping org.apache.spark.deploy.worker.Worker
Ubuntu-03: stopping org.apache.spark.deploy.worker.Worker
Ubuntu-01: stopping org.apache.spark.deploy.worker.Worker
hadoop@Ubuntu-01:~$ stop-master.sh
stopping org.apache.spark.deploy.master.Master
hadoop@Ubuntu-01:~$ stop-yarn.sh
stopping yarn daemons
stopping resourcemanager
Ubuntu-03: stopping nodemanager
Ubuntu-02: stopping nodemanager
no proxyserver to stop
hadoop@Ubuntu-01:~$ stop-dfs.sh
Stopping namenodes on [Ubuntu-01]
Ubuntu-01: stopping namenode
Ubuntu-02: stopping datanode
Ubuntu-03: stopping datanode
Stopping secondary namenodes [Ubuntu-01]
Ubuntu-01: stopping secondarynamenode
Scala-IDE搭建Spark源码分析环境
下载、解压Scala-IDE,下载地址为: http://scala-ide.org/index.html scala-SDK-4.5.0-vfinal-2.11-win32.win32.x86_64.zip
下载、安装SBT,下载地址为: http://www.scala-sbt.org/ sbt-0.13.13.1.msi
在github上下载最新的Spark源码:
PS D:\temp\Scala> git clone https://github.com/apache/spark.git
PS D:\temp\Scala> cd .\spark\
输入sbt命令,首次会下载很多东西,速度比较慢,某些在墙外,所以需要提前搭建VPN。如果出错可以多执行几遍
PS D:\temp\Scala\spark> sbt
ignoring option MaxPermSize=256m; support was removed in 8.0
[info] Loading project definition from D:\temp\Scala\spark\project
[info] Resolving key references (18753 settings) ...
[info] Set current project to spark-parent (in build file:/D:/temp/Scala/spark/)
在sbt提示符下输入eclipse,首次会下载很多东西,速度比较慢。如果出错多执行几遍。
> eclipse
[info] About to create Eclipse project files for your project(s).
[info] Resolving jline#jline;2.12.1 ...
[info] Successfully created Eclipse project files for project(s):
[info] spark-sql
[info] spark-sql-kafka-0-10
[info] spark-streaming-kafka-0-8-assembly
[info] spark-examples
[info] spark-streaming
[info] spark-mllib
[info] spark-catalyst
[info] spark-streaming-kafka-0-10-assembly
[info] spark-graphx
[info] spark-streaming-flume-sink
[info] spark-tags
[info] spark-assembly
[info] spark-mllib-local
[info] spark-tools
[info] spark-repl
[info] spark-streaming-flume-assembly
[info] spark-streaming-kafka-0-8
[info] old-deps
[info] spark-network-common
[info] spark-hive
[info] spark-streaming-flume
[info] spark-sketch
[info] spark-network-shuffle
[info] spark-core
[info] spark-unsafe
[info] spark-streaming-kafka-0-10
[info] spark-launcher
> exit
在Scala-IDE导入spark项目:
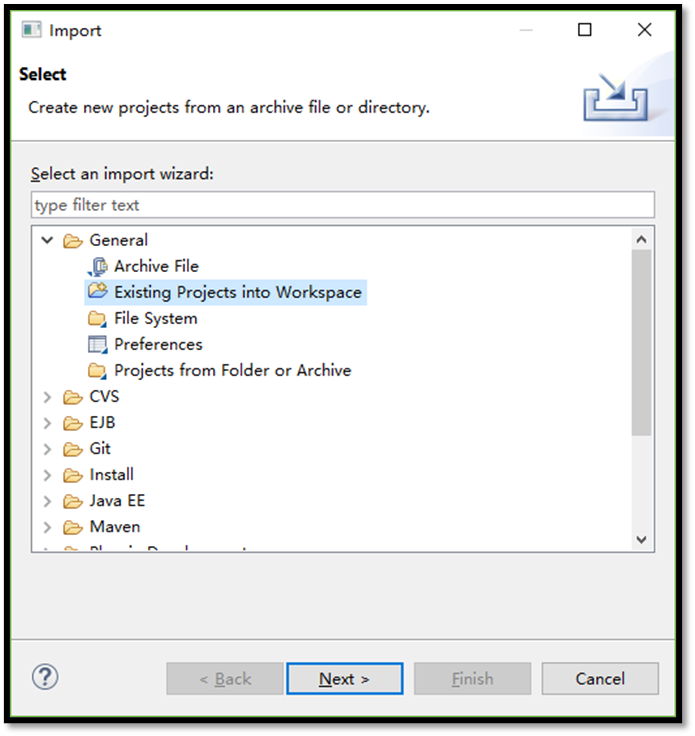
安装Zookeeper
https://zookeeper.apache.org/
zookeeper-3.4.9.tar.gz
hadoop@Ubuntu-01:~$ cd /usr/local
hadoop@Ubuntu-01:/usr/local$ sudo mkdir zookeeper
hadoop@Ubuntu-01:/usr/local$ sudo chown hadoop:hadoop zookeeper/
hadoop@Ubuntu-01:/usr/local$ cd zookeeper/
hadoop@Ubuntu-01:/usr/local/zookeeper$ tar -zxvf zookeeper-3.4.9.tar.gz
hadoop@Ubuntu-01:/usr/local/zookeeper$ sudo vim /etc/profile
export ZOOKEEPER_HOME=/usr/local/zookeeper/zookeeper-3.4.9
export PATH=$PATH:$ZOOKEEPER_HOME/bin
hadoop@Ubuntu-01:/usr/local/zookeeper$ source /etc/profile
hadoop@Ubuntu-01:/usr/local/zookeeper/ $ cd zookeeper-3.4.9/conf
hadoop@Ubuntu-01:/usr/local/zookeeper/zookeeper-3.4.9/conf$ cp zoo_sample.cfg zoo.cfg
hadoop@Ubuntu-01:/usr/local/zookeeper/zookeeper-3.4.9/conf$ vim zoo.cfg
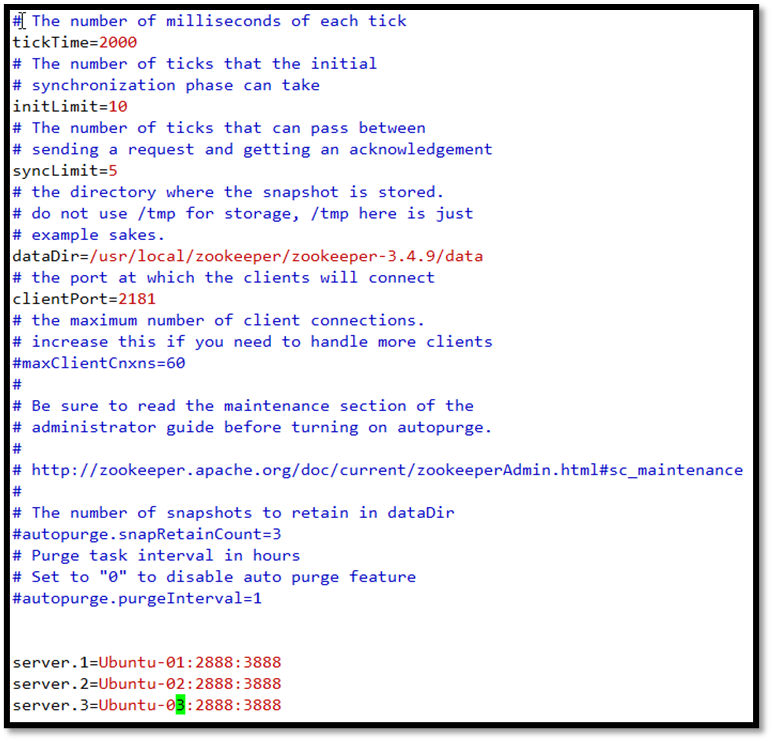
将dataDir改为dataDir=/usr/local/zookeeper/zookeeper-3.4.9/data(该目录需要新建),在文件末位添加所有的主机,注意server后面的数字需要与myid文件中的数字保持一致。
hadoop@Ubuntu-01:/usr/local/zookeeper/zookeeper-3.4.9$ mkdir data
hadoop@Ubuntu-01:/usr/local/zookeeper/zookeeper-3.4.9$ cd data/
hadoop@Ubuntu-01:/usr/local/zookeeper/zookeeper-3.4.9/data$ vim myid
myid中写入1
对Ubuntu-02与Ubuntu-03机器进行类似操作,在各主机myid文件中写入各自的编号。
hadoop@Ubuntu-01:/usr/local/zookeeper$ scp -r zookeeper-3.4.9/ hadoop@Ubuntu-02:/usr/local/zookeeper/
hadoop@Ubuntu-01:/usr/local/zookeeper$ scp -r zookeeper-3.4.9/ hadoop@Ubuntu-03:/usr/local/zookeeper/
验证
在每台zookeeper机器上执行:
hadoop@Ubuntu-01:~$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/zookeeper-3.4.9/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
hadoop@Ubuntu-02:~$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/zookeeper-3.4.9/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
hadoop@Ubuntu-03:~$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/zookeeper-3.4.9/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
hadoop@Ubuntu-01:~$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: follower
hadoop@Ubuntu-02:~$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: leader
hadoop@Ubuntu-03:~$ zkServer.sh status
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/zookeeper-3.4.9/bin/../conf/zoo.cfg
Mode: follower
hadoop@Ubuntu-01:~$ zkCli.sh -server Ubuntu-01:2181
Connecting to Ubuntu-01:2181
2017-02-18 22:32:23,226 [myid:] - INFO [main:Environment@100] - Client environment:zookeeper.version=3.4.9-1757313, built on 08/23/2016 06:50 GMT
2017-02-18 22:32:23,231 [myid:] - INFO [main:Environment@100] - Client environment:host.name=Ubuntu-01
2017-02-18 22:32:23,231 [myid:] - INFO [main:Environment@100] - Client environment:java.version=1.8.0_121
2017-02-18 22:32:23,233 [myid:] - INFO [main:Environment@100] - Client environment:java.vendor=Oracle Corporation
2017-02-18 22:32:23,233 [myid:] - INFO [main:Environment@100] - Client environment:java.home=/usr/local/java/jdk1.8.0_121/jre
2017-02-18 22:32:23,233 [myid:] - INFO [main:Environment@100] - Client environment:java.class.path=/usr/local/zookeeper/zookeeper-3.4.9/bin/../build/classes:/usr/local/zookeeper/zookeeper-3.4.9/bin/../build/lib/*.jar:/usr/local/zookeeper/zookeeper-3.4.9/bin/../lib/slf4j-log4j12-1.6.1.jar:/usr/local/zookeeper/zookeeper-3.4.9/bin/../lib/slf4j-api-1.6.1.jar:/usr/local/zookeeper/zookeeper-3.4.9/bin/../lib/netty-3.10.5.Final.jar:/usr/local/zookeeper/zookeeper-3.4.9/bin/../lib/log4j-1.2.16.jar:/usr/local/zookeeper/zookeeper-3.4.9/bin/../lib/jline-0.9.94.jar:/usr/local/zookeeper/zookeeper-3.4.9/bin/../zookeeper-3.4.9.jar:/usr/local/zookeeper/zookeeper-3.4.9/bin/../src/java/lib/*.jar:/usr/local/zookeeper/zookeeper-3.4.9/bin/../conf:.:/usr/local/java/jdk1.8.0_121/lib:.:/usr/local/java/jdk1.8.0_121/lib:.:/usr/local/java/jdk1.8.0_121/lib:
2017-02-18 22:32:23,234 [myid:] - INFO [main:Environment@100] - Client environment:java.library.path=/usr/java/packages/lib/amd64:/usr/lib64:/lib64:/lib:/usr/lib
2017-02-18 22:32:23,234 [myid:] - INFO [main:Environment@100] - Client environment:java.io.tmpdir=/tmp
2017-02-18 22:32:23,234 [myid:] - INFO [main:Environment@100] - Client environment:java.compiler=<NA>
2017-02-18 22:32:23,235 [myid:] - INFO [main:Environment@100] - Client environment:os.name=Linux
2017-02-18 22:32:23,235 [myid:] - INFO [main:Environment@100] - Client environment:os.arch=amd64
2017-02-18 22:32:23,235 [myid:] - INFO [main:Environment@100] - Client environment:os.version=4.4.0-62-generic
2017-02-18 22:32:23,235 [myid:] - INFO [main:Environment@100] - Client environment:user.name=hadoop
2017-02-18 22:32:23,236 [myid:] - INFO [main:Environment@100] - Client environment:user.home=/home/hadoop
2017-02-18 22:32:23,236 [myid:] - INFO [main:Environment@100] - Client environment:user.dir=/home/hadoop
2017-02-18 22:32:23,237 [myid:] - INFO [main:ZooKeeper@438] - Initiating client connection, connectString=Ubuntu-01:2181 sessionTimeout=30000 watcher=org.apache.zookeeper.ZooKeeperMain$MyWatcher@531d72ca
Welcome to ZooKeeper!
2017-02-18 22:32:23,268 [myid:] - INFO [main-SendThread(Ubuntu-01:2181):ClientCnxn$SendThread@1032] - Opening socket connection to server Ubuntu-01/192.168.1.160:2181. Will not attempt to authenticate using SASL (unknown error)
JLine support is enabled
2017-02-18 22:32:23,398 [myid:] - INFO [main-SendThread(Ubuntu-01:2181):ClientCnxn$SendThread@876] - Socket connection established to Ubuntu-01/192.168.1.160:2181, initiating session
2017-02-18 22:32:23,429 [myid:] - INFO [main-SendThread(Ubuntu-01:2181):ClientCnxn$SendThread@1299] - Session establishment complete on server Ubuntu-01/192.168.1.160:2181, sessionid = 0x15a51a0e47d0000, negotiated timeout = 30000
WATCHER::
WatchedEvent state:SyncConnected type:None path:null
[zk: Ubuntu-01:2181(CONNECTED) 0] quit
Quitting...
2017-02-18 22:32:34,993 [myid:] - INFO [main-EventThread:ClientCnxn$EventThread@519] - EventThread shut down for session: 0x15a51a0e47d0000
2017-02-18 22:32:34,994 [myid:] - INFO [main:ZooKeeper@684] - Session: 0x15a51a0e47d0000 closed
hadoop@Ubuntu-01:~$ echo ruok| nc Ubuntu-01 2181
imokhadoop@Ubuntu-01:~$
安装HBase
下载地址:http://hbase.apache.org/ 安装版本:hbase-1.2.4-bin.tar.gz
hadoop@Ubuntu-01:~$ cd /usr/local
hadoop@Ubuntu-01:/usr/local$ sudo mkdir hbase
hadoop@Ubuntu-01:/usr/local$ sudo chown hadoop:hadoop hbase/
hadoop@Ubuntu-01:/usr/local$ cd hbase/
hadoop@Ubuntu-01:/usr/local/hbase$ tar -zxvf hbase-1.2.4-bin.tar.gz
hadoop@Ubuntu-01:/usr/local/spark$ sudo vim /etc/profile
export HBASE_HOME=/usr/local/hbase/hbase-1.2.4
export PATH=$PATH:$HBASE_HOME/bin
export HBASE_CLASSPATH=$HBASE_HOME/lib
hadoop@Ubuntu-01:/usr/local/spark$ source /etc/profile
hadoop@Ubuntu-01:/usr/local/hbase$ cd hbase-1.2.4/conf
hadoop@Ubuntu-01:/usr/local/hbase/hbase-1.2.4/conf$ vim hbase-env.sh
取消JAVA_HOME和HBASE_MANAGES_ZK项的注释,并设置正确值。
export JAVA_HOME=/usr/local/java/jdk1.8.0_121
export HBASE_MANAGES_ZK=false
hadoop@Ubuntu-01:/usr/local/hbase/hbase-1.2.4/conf$ vim hbase-site.xml
<configuration>
<property>
<name>hbase.rootdir</name>
<value>hdfs://Ubuntu-01:9000/hbase</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<property>
<name>hbase.zookeeper.quorum</name>
<value>Ubuntu-01,Ubuntu-02,Ubuntu-03</value>
</property>
</configuration>
复制到另外两个节点
hadoop@Ubuntu-01:/usr/local/hbase$ scp -r hbase-1.2.4 hadoop@Ubuntu-02:/usr/local/hbase/
hadoop@Ubuntu-01:/usr/local/hbase$ scp -r hbase-1.2.4 hadoop@Ubuntu-03:/usr/local/hbase/
验证
启动
除了zkServer.sh start要在所有节点执行外,其余启动命令只需要在主节点执行
hadoop@Ubuntu-01:~$ start-dfs.sh
Starting namenodes on [Ubuntu-01]
Ubuntu-01: starting namenode, logging to /usr/local/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-namenode-Ubuntu-01.out
Ubuntu-02: starting datanode, logging to /usr/local/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-Ubuntu-02.out
Ubuntu-03: starting datanode, logging to /usr/local/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-Ubuntu-03.out
Starting secondary namenodes [Ubuntu-01]
Ubuntu-01: starting secondarynamenode, logging to /usr/local/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-secondarynamenode-Ubuntu-01.out
hadoop@Ubuntu-01:~$ jps
10835 Jps
10518 NameNode
4299 SecondaryNameNode
hadoop@Ubuntu-01:~$ zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/zookeeper-3.4.9/bin/../conf/zoo.cfg
Starting zookeeper ... STARTED
hadoop@Ubuntu-01:~$ jps
10518 NameNode
10854 QuorumPeerMain
4299 SecondaryNameNode
10879 Jps
hadoop@Ubuntu-01:~$ start-hbase.sh
starting master, logging to /usr/local/hbase/hbase-1.2.4/logs/hbase-hadoop-master-Ubuntu-01.out
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option PermSize=128m; support was removed in 8.0
Java HotSpot(TM) 64-Bit Server VM warning: ignoring option MaxPermSize=128m; support was removed in 8.0
hadoop@Ubuntu-01:~$ jps
10518 NameNode
10854 QuorumPeerMain
11015 HMaster
11191 Jps
4299 SecondaryNameNode
hadoop@Ubuntu-01:~$ hbase shell
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hbase/hbase-1.2.4/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
HBase Shell; enter 'help<RETURN>' for list of supported commands.
Type "exit<RETURN>" to leave the HBase Shell
Version 1.2.4, r67592f3d062743907f8c5ae00dbbe1ae4f69e5af, Tue Oct 25 18:10:20 CDT 2016
hbase(main):001:0>
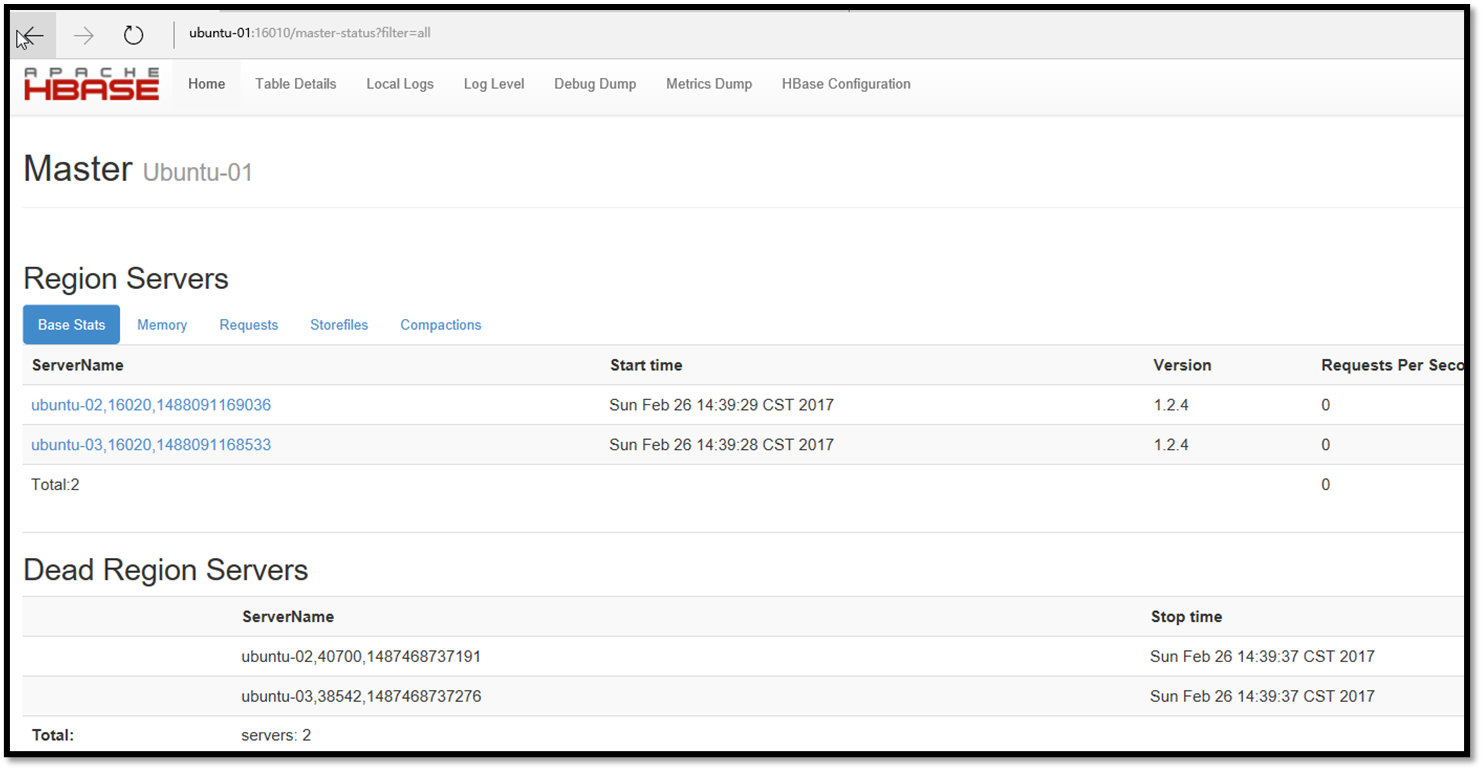
查看hbase管理界面
http://ubuntu-01:16010/
关闭
除了zkServer.sh stop要在所有节点执行外,其余关闭命令只需要在主节点执行
hadoop@Ubuntu-01:~$ jps
11297 Jps
10518 NameNode
10854 QuorumPeerMain
11015 HMaster
4299 SecondaryNameNode
hadoop@Ubuntu-01:~$ stop-hbase.sh
stopping hbase................
hadoop@Ubuntu-01:~$ jps
10518 NameNode
10854 QuorumPeerMain
4299 SecondaryNameNode
11516 Jps
hadoop@Ubuntu-01:~$ zkServer.sh stop
ZooKeeper JMX enabled by default
Using config: /usr/local/zookeeper/zookeeper-3.4.9/bin/../conf/zoo.cfg
Stopping zookeeper ... STOPPED
hadoop@Ubuntu-01:~$ jps
11537 Jps
10518 NameNode
4299 SecondaryNameNode
hadoop@Ubuntu-01:~$ stop-dfs.sh
Stopping namenodes on [Ubuntu-01]
Ubuntu-01: stopping namenode
Ubuntu-02: stopping datanode
Ubuntu-03: stopping datanode
Stopping secondary namenodes [Ubuntu-01]
hadoop@Ubuntu-01:~$ jps
11880 Jps
安装Hive
http://hive.apache.org/
apache-hive-2.1.1-bin.tar.gz
hadoop@Ubuntu-01:~$ cd /usr/local
hadoop@Ubuntu-01:/usr/local$ sudo mkdir hive
hadoop@Ubuntu-01:/usr/local$ sudo chown hadoop:hadoop hive/
hadoop@Ubuntu-01:/usr/local$ cd hive/
hadoop@Ubuntu-01:/usr/local/hive$ tar -zxvf apache-hive-2.1.1-bin.tar.gz
hadoop@Ubuntu-01:/usr/local/hive$ sudo vim /etc/profile
export HIVE_HOME=/usr/local/hive/apache-hive-2.1.1-bin
export PATH=$PATH:$HIVE_HOME/bin
hadoop@Ubuntu-01:/usr/local/hive$ source /etc/profile
hadoop@Ubuntu-01:/usr/local/hive$ cd apache-hive-2.1.1-bin/conf/
hadoop@Ubuntu-01:/usr/local/hive/apache-hive-2.1.1-bin/conf$ cp hive-default.xml.template hive-site.xml
hadoop@Ubuntu-01:/usr/local/hive/apache-hive-2.1.1-bin/conf$ vim hive-site.xml
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://192.168.1.100:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>hive</value>
<description>username to use against metastore database</description>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>hive</value>
</property>
<property>
<name>hive.hwi.listen.port</name>
<value>9999</value>
<description>This is the port the Hive Web Interface will listen on</description>
</property>
<property>
<name>datanucleus.autoCreateSchema</name>
<value>false</value>
</property>
<property>
<name>datanucleus.fixedDatastore</name>
<value>true</value>
</property>
<property>
<name>hive.metastore.local</name>
<value>true</value>
<description>controls whether to connect to remove metastore server or open a new metastore server in Hive Client JVM</description>
</property>
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
<description>
Enforce metastore schema version consistency.
True: Verify that version information stored in metastore matches with one from Hive jars. Also disable automatic
schema migration attempt. Users are required to manully migrate schema after Hive upgrade which ensures
proper metastore schema migration. (Default)
False: Warn if the version information stored in metastore doesn't match with one from in Hive jars.
</description>
</property>
</configuration>
下载mysql连接java的驱动 并拷入hive home的lib下(mysql-connector-java-5.1.38.jar)
hadoop@Ubuntu-01:~$ schematool -initSchema -dbType mysql
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hive/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Metastore connection URL: jdbc:mysql://192.168.1.100:3306/hive?createDatabaseIfNotExist=true
Metastore Connection Driver : com.mysql.jdbc.Driver
Metastore connection User: hive
Starting metastore schema initialization to 2.1.0
Initialization script hive-schema-2.1.0.mysql.sql
Initialization script completed
schemaTool completed
hadoop@Ubuntu-01:~$ start-dfs.sh
Starting namenodes on [Ubuntu-01]
Ubuntu-01: starting namenode, logging to /usr/local/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-namenode-Ubuntu-01.out
Ubuntu-02: starting datanode, logging to /usr/local/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-Ubuntu-02.out
Ubuntu-03: starting datanode, logging to /usr/local/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-datanode-Ubuntu-03.out
Starting secondary namenodes [Ubuntu-01]
Ubuntu-01: starting secondarynamenode, logging to /usr/local/hadoop/hadoop-2.7.3/logs/hadoop-hadoop-secondarynamenode-Ubuntu-01.out
hadoop@Ubuntu-01:~$ hive
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hive/apache-hive-2.1.1-bin/lib/log4j-slf4j-impl-2.4.1.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.apache.logging.slf4j.Log4jLoggerFactory]
Logging initialized using configuration in jar:file:/usr/local/hive/apache-hive-2.1.1-bin/lib/hive-common-2.1.1.jar!/hive-log4j2.properties Async: true
Hive-on-MR is deprecated in Hive 2 and may not be available in the future versions. Consider using a different execution engine (i.e. spark, tez) or using Hive 1.X releases.
hive>
create database hive;
-- 创建hive用户,并授权
grant all on hive.* to hive@'%' identified by 'hive';
flush privileges;
安装PIG
http://pig.apache.org/ pig-0.16.0.tar.gz
hadoop@Ubuntu-01:~$ cd /usr/local
hadoop@Ubuntu-01:/usr/local$ sudo mkdir pig
hadoop@Ubuntu-01:/usr/local$ sudo chown hadoop:hadoop pig/
hadoop@Ubuntu-01:/usr/local$ cd pig/
hadoop@Ubuntu-01:/usr/local/pig$ tar -zxvf pig-0.16.0.tar.gz
hadoop@Ubuntu-01:/usr/local/pig$ sudo vim /etc/profile
export PIG_HOME=/usr/local/pig/pig-0.16.0
export PATH=$PATH:$PIG_HOME/bin
export PIG_CLASSPATH=$HADDOP_HOME/conf
hadoop@Ubuntu-01:/usr/local/pig$ source /etc/profile
测试
hadoop@Ubuntu-01:~$ pig -x local
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hbase/hbase-1.2.4/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
17/02/24 22:26:57 INFO pig.ExecTypeProvider: Trying ExecType : LOCAL
17/02/24 22:26:57 INFO pig.ExecTypeProvider: Picked LOCAL as the ExecType
2017-02-24 22:26:57,715 [main] INFO org.apache.pig.Main - Apache Pig version 0.16.0 (r1746530) compiled Jun 01 2016, 23:10:49
2017-02-24 22:26:57,715 [main] INFO org.apache.pig.Main - Logging error messages to: /home/hadoop/pig_1487946417711.log
2017-02-24 22:26:57,754 [main] INFO org.apache.pig.impl.util.Utils - Default bootup file /home/hadoop/.pigbootup not found
2017-02-24 22:26:58,045 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
2017-02-24 22:26:58,046 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - fs.default.name is deprecated. Instead, use fs.defaultFS
2017-02-24 22:26:58,048 [main] INFO org.apache.pig.backend.hadoop.executionengine.HExecutionEngine - Connecting to hadoop file system at: file:///
2017-02-24 22:26:58,344 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - io.bytes.per.checksum is deprecated. Instead, use dfs.bytes-per-checksum
2017-02-24 22:26:58,374 [main] INFO org.apache.pig.PigServer - Pig Script ID for the session: PIG-default-7efc5f81-68bd-4e67-aa0d-30882be88c11
2017-02-24 22:26:58,375 [main] WARN org.apache.pig.PigServer - ATS is disabled since yarn.timeline-service.enabled set to false
grunt> quit
2017-02-24 22:30:50,757 [main] INFO org.apache.pig.Main - Pig script completed in 3 minutes, 53 seconds and 947 milliseconds (233947 ms)
hadoop@Ubuntu-01:~$ pig
17/02/24 22:32:52 INFO pig.ExecTypeProvider: Trying ExecType : LOCAL
17/02/24 22:32:52 INFO pig.ExecTypeProvider: Trying ExecType : MAPREDUCE
17/02/24 22:32:52 INFO pig.ExecTypeProvider: Picked MAPREDUCE as the ExecType
2017-02-24 22:32:52,844 [main] INFO org.apache.pig.Main - Apache Pig version 0.16.0 (r1746530) compiled Jun 01 2016, 23:10:49
2017-02-24 22:32:52,845 [main] INFO org.apache.pig.Main - Logging error messages to: /home/hadoop/pig_1487946772836.log
2017-02-24 22:32:52,890 [main] INFO org.apache.pig.impl.util.Utils - Default bootup file /home/hadoop/.pigbootup not found
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/usr/local/hadoop/hadoop-2.7.3/share/hadoop/common/lib/slf4j-log4j12-1.7.10.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/usr/local/hbase/hbase-1.2.4/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2017-02-24 22:32:53,865 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - mapred.job.tracker is deprecated. Instead, use mapreduce.jobtracker.address
2017-02-24 22:32:53,866 [main] INFO org.apache.hadoop.conf.Configuration.deprecation - fs.default.name is deprecated. Instead, use fs.defaultFS
2017-02-24 22:32:53,866 [main] INFO org.apache.pig.backend.hadoop.executionengine.HExecutionEngine - Connecting to hadoop file system at: hdfs://Ubuntu-01:9000
2017-02-24 22:32:54,752 [main] INFO org.apache.pig.PigServer - Pig Script ID for the session: PIG-default-aeeb7102-d88a-4154-9876-d76ff0da3a8c
2017-02-24 22:32:54,752 [main] WARN org.apache.pig.PigServer - ATS is disabled since yarn.timeline-service.enabled set to false
grunt> ls /
hdfs://Ubuntu-01:9000/hbase <dir>
hdfs://Ubuntu-01:9000/output <dir>
hdfs://Ubuntu-01:9000/tmp <dir>
安装Mahout
http://mahout.apache.org/ apache-mahout-distribution-0.12.2.tar.gz
hadoop@Ubuntu-01:~$ cd /usr/local
hadoop@Ubuntu-01:/usr/local$ sudo mkdir mahout
hadoop@Ubuntu-01:/usr/local$ sudo chown hadoop:hadoop mahout/
hadoop@Ubuntu-01:/usr/local$ cd mahout/
hadoop@Ubuntu-01:/usr/local/mahout$ tar -zxvf apache-mahout-distribution-0.12.2.tar.gz
hadoop@Ubuntu-01:/usr/local/mahout$ sudo vim /etc/profile
export MAHOUT_HOME=/usr/local/mahout/apache-mahout-distribution-0.12.2
export PATH=$PATH:$MAHOUT_HOME/bin
hadoop@Ubuntu-01:/usr/local/mahout$ source /etc/profile
hadoop@Ubuntu-01:~$ cd
hadoop@Ubuntu-01:~$ start-dfs.sh
hadoop@Ubuntu-01:~$ start-yarn.sh
hadoop@Ubuntu-01:~$ mahout –help
Running on hadoop, using /usr/local/hadoop/hadoop-2.7.3/bin/hadoop and HADOOP_CONF_DIR=
MAHOUT-JOB: /usr/local/mahout/apache-mahout-distribution-0.12.2/mahout-examples-0.12.2-job.jar
Unknown program '--help' chosen.
Valid program names are:
arff.vector: : Generate Vectors from an ARFF file or directory
baumwelch: : Baum-Welch algorithm for unsupervised HMM training
canopy: : Canopy clustering
cat: : Print a file or resource as the logistic regression models would see it
cleansvd: : Cleanup and verification of SVD output
clusterdump: : Dump cluster output to text
clusterpp: : Groups Clustering Output In Clusters
cmdump: : Dump confusion matrix in HTML or text formats
cvb: : LDA via Collapsed Variation Bayes (0th deriv. approx)
cvb0_local: : LDA via Collapsed Variation Bayes, in memory locally.
describe: : Describe the fields and target variable in a data set
evaluateFactorization: : compute RMSE and MAE of a rating matrix factorization against probes
fkmeans: : Fuzzy K-means clustering
hmmpredict: : Generate random sequence of observations by given HMM
itemsimilarity: : Compute the item-item-similarities for item-based collaborative filtering
kmeans: : K-means clustering
lucene.vector: : Generate Vectors from a Lucene index
matrixdump: : Dump matrix in CSV format
matrixmult: : Take the product of two matrices
parallelALS: : ALS-WR factorization of a rating matrix
qualcluster: : Runs clustering experiments and summarizes results in a CSV
recommendfactorized: : Compute recommendations using the factorization of a rating matrix
recommenditembased: : Compute recommendations using item-based collaborative filtering
regexconverter: : Convert text files on a per line basis based on regular expressions
resplit: : Splits a set of SequenceFiles into a number of equal splits
rowid: : Map SequenceFile<Text,VectorWritable> to {SequenceFile<IntWritable,VectorWritable>, SequenceFile<IntWritable,Text>}
rowsimilarity: : Compute the pairwise similarities of the rows of a matrix
runAdaptiveLogistic: : Score new production data using a probably trained and validated AdaptivelogisticRegression model
runlogistic: : Run a logistic regression model against CSV data
seq2encoded: : Encoded Sparse Vector generation from Text sequence files
seq2sparse: : Sparse Vector generation from Text sequence files
seqdirectory: : Generate sequence files (of Text) from a directory
seqdumper: : Generic Sequence File dumper
seqmailarchives: : Creates SequenceFile from a directory containing gzipped mail archives
seqwiki: : Wikipedia xml dump to sequence file
spectralkmeans: : Spectral k-means clustering
split: : Split Input data into test and train sets
splitDataset: : split a rating dataset into training and probe parts
ssvd: : Stochastic SVD
streamingkmeans: : Streaming k-means clustering
svd: : Lanczos Singular Value Decomposition
testnb: : Test the Vector-based Bayes classifier
trainAdaptiveLogistic: : Train an AdaptivelogisticRegression model
trainlogistic: : Train a logistic regression using stochastic gradient descent
trainnb: : Train the Vector-based Bayes classifier
transpose: : Take the transpose of a matrix
validateAdaptiveLogistic: : Validate an AdaptivelogisticRegression model against hold-out data set
vecdist: : Compute the distances between a set of Vectors (or Cluster or Canopy, they must fit in memory) and a list of Vectors
vectordump: : Dump vectors from a sequence file to text
viterbi: : Viterbi decoding of hidden states from given output states sequence
hadoop@Ubuntu-01:~$ hadoop fs -mkdir /user
hadoop@Ubuntu-01:~$ hadoop fs -mkdir /user/Hadoop
hadoop@Ubuntu-01:~$ hadoop fs -mkdir /user/hadoop/testdata
hadoop@Ubuntu-01:~$ hadoop fs -put big-data-demo/synthetic_control.data.txt /user/hadoop/testdata
hadoop@Ubuntu-01:~$ hadoop jar /usr/local/mahout/apache-mahout-distribution-0.12.2/mahout-examples-0.12.2-job.jar org.apache.mahout.clustering.syntheticcontrol.kmeans.Job
hadoop@Ubuntu-01:~$ hadoop fs -ls -R output
-rw-r--r-- 2 hadoop supergroup 194 2017-03-01 22:21 output/_policy
drwxr-xr-x - hadoop supergroup 0 2017-03-01 22:21 output/clusteredPoints
-rw-r--r-- 2 hadoop supergroup 0 2017-03-01 22:21 output/clusteredPoints/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 363282 2017-03-01 22:21 output/clusteredPoints/part-m-00000
drwxr-xr-x - hadoop supergroup 0 2017-03-01 22:16 output/clusters-0
-rw-r--r-- 2 hadoop supergroup 194 2017-03-01 22:16 output/clusters-0/_policy
-rw-r--r-- 2 hadoop supergroup 1891 2017-03-01 22:16 output/clusters-0/part-00000
-rw-r--r-- 2 hadoop supergroup 1891 2017-03-01 22:16 output/clusters-0/part-00001
-rw-r--r-- 2 hadoop supergroup 1891 2017-03-01 22:16 output/clusters-0/part-00002
-rw-r--r-- 2 hadoop supergroup 1891 2017-03-01 22:16 output/clusters-0/part-00003
-rw-r--r-- 2 hadoop supergroup 1891 2017-03-01 22:16 output/clusters-0/part-00004
-rw-r--r-- 2 hadoop supergroup 1891 2017-03-01 22:16 output/clusters-0/part-00005
drwxr-xr-x - hadoop supergroup 0 2017-03-01 22:16 output/clusters-1
-rw-r--r-- 2 hadoop supergroup 0 2017-03-01 22:16 output/clusters-1/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 194 2017-03-01 22:16 output/clusters-1/_policy
-rw-r--r-- 2 hadoop supergroup 7581 2017-03-01 22:16 output/clusters-1/part-r-00000
drwxr-xr-x - hadoop supergroup 0 2017-03-01 22:21 output/clusters-10-final
-rw-r--r-- 2 hadoop supergroup 0 2017-03-01 22:21 output/clusters-10-final/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 194 2017-03-01 22:21 output/clusters-10-final/_policy
-rw-r--r-- 2 hadoop supergroup 7581 2017-03-01 22:21 output/clusters-10-final/part-r-00000
drwxr-xr-x - hadoop supergroup 0 2017-03-01 22:17 output/clusters-2
-rw-r--r-- 2 hadoop supergroup 0 2017-03-01 22:17 output/clusters-2/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 194 2017-03-01 22:17 output/clusters-2/_policy
-rw-r--r-- 2 hadoop supergroup 7581 2017-03-01 22:17 output/clusters-2/part-r-00000
drwxr-xr-x - hadoop supergroup 0 2017-03-01 22:17 output/clusters-3
-rw-r--r-- 2 hadoop supergroup 0 2017-03-01 22:17 output/clusters-3/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 194 2017-03-01 22:17 output/clusters-3/_policy
-rw-r--r-- 2 hadoop supergroup 7581 2017-03-01 22:17 output/clusters-3/part-r-00000
drwxr-xr-x - hadoop supergroup 0 2017-03-01 22:18 output/clusters-4
-rw-r--r-- 2 hadoop supergroup 0 2017-03-01 22:18 output/clusters-4/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 194 2017-03-01 22:18 output/clusters-4/_policy
-rw-r--r-- 2 hadoop supergroup 7581 2017-03-01 22:18 output/clusters-4/part-r-00000
drwxr-xr-x - hadoop supergroup 0 2017-03-01 22:18 output/clusters-5
-rw-r--r-- 2 hadoop supergroup 0 2017-03-01 22:18 output/clusters-5/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 194 2017-03-01 22:18 output/clusters-5/_policy
-rw-r--r-- 2 hadoop supergroup 7581 2017-03-01 22:18 output/clusters-5/part-r-00000
drwxr-xr-x - hadoop supergroup 0 2017-03-01 22:19 output/clusters-6
-rw-r--r-- 2 hadoop supergroup 0 2017-03-01 22:19 output/clusters-6/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 194 2017-03-01 22:19 output/clusters-6/_policy
-rw-r--r-- 2 hadoop supergroup 7581 2017-03-01 22:19 output/clusters-6/part-r-00000
drwxr-xr-x - hadoop supergroup 0 2017-03-01 22:19 output/clusters-7
-rw-r--r-- 2 hadoop supergroup 0 2017-03-01 22:19 output/clusters-7/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 194 2017-03-01 22:19 output/clusters-7/_policy
-rw-r--r-- 2 hadoop supergroup 7581 2017-03-01 22:19 output/clusters-7/part-r-00000
drwxr-xr-x - hadoop supergroup 0 2017-03-01 22:20 output/clusters-8
-rw-r--r-- 2 hadoop supergroup 0 2017-03-01 22:20 output/clusters-8/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 194 2017-03-01 22:20 output/clusters-8/_policy
-rw-r--r-- 2 hadoop supergroup 7581 2017-03-01 22:20 output/clusters-8/part-r-00000
drwxr-xr-x - hadoop supergroup 0 2017-03-01 22:20 output/clusters-9
-rw-r--r-- 2 hadoop supergroup 0 2017-03-01 22:20 output/clusters-9/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 194 2017-03-01 22:20 output/clusters-9/_policy
-rw-r--r-- 2 hadoop supergroup 7581 2017-03-01 22:20 output/clusters-9/part-r-00000
drwxr-xr-x - hadoop supergroup 0 2017-03-01 22:16 output/data
-rw-r--r-- 2 hadoop supergroup 0 2017-03-01 22:16 output/data/_SUCCESS
-rw-r--r-- 2 hadoop supergroup 335470 2017-03-01 22:16 output/data/part-m-00000
drwxr-xr-x - hadoop supergroup 0 2017-03-01 22:16 output/random-seeds
-rw-r--r-- 2 hadoop supergroup 7723 2017-03-01 22:16 output/random-seeds/part-randomSeed
使用Ambari安装Hadoop集群
ubuntu-16.04.1-04 ubuntu-16.04.1-05 ubuntu-16.04.1-06三台虚拟机已经拆除,如果需要再次尝试Ambari需要重新创建虚拟机。
基础环境搭建
配置主机名,安装JDK,配置SSH互登陆等参考前文所述方法,配置SSH互登陆过程中要使用root用户,在配置过程中,如果scp命令不允许使用root用户远程访问,参考下面的方法解决:
root@Ubuntu-04:~# vi /etc/ssh/sshd_config
# Authentication:
LoginGraceTime 120
PermitRootLogin yes
#PermitRootLogin prohibit-password
StrictModes yes
重启 ssh 服务
root@Ubuntu-04:~# service ssh restart
另外由于Ambari最新版本的安装需要Maven,所以在某个节点上使用下面方式安装Maven:
root@Ubuntu-04:~# mkdir /usr/local/maven
root@Ubuntu-04:~# cd /usr/local/maven/
root@Ubuntu-04:/usr/local/maven# ls
apache-maven-3.5.0-bin.tar.gz
root@Ubuntu-04:/usr/local/maven# tar -zxvf apache-maven-3.5.0-bin.tar.gz
root@Ubuntu-04:/usr/local/maven# sudo vim /etc/profile
export M2_HOME=/usr/local/maven/apache-maven-3.5.0
export PATH=$PATH:$M2_HOME/bin
root@Ubuntu-04:/usr/local/maven# source /etc/profile
安装Ambari
主要参考官方文档:https://cwiki.apache.org/confluence/display/AMBARI/Installation+Guide+for+Ambari+2.5.1
在其中一个节点(安装maven的节点)下载ambari的源码包,并打包成deb包,拷贝到所有其它节点进行安装。
root@Ubuntu-04:~# mkdir /usr/local/ambary
root@Ubuntu-04:~# cd /usr/local/ambari/
root@Ubuntu-04:/usr/local/ambari# wget http://www.apache.org/dist/ambari/ambari-2.5.1/apache-ambari-2.5.1-src.tar.gz
root@Ubuntu-04:/usr/local/ambari# tar xfvz apache-ambari-2.5.1-src.tar.gz
root@Ubuntu-04:/usr/local/ambari# cd apache-ambari-2.5.1-src
root@Ubuntu-04:/usr/local/ambari/apache-ambari-2.5.1-src# mvn versions:set -DnewVersion=2.5.1.0.0
root@Ubuntu-04:/usr/local/ambari/apache-ambari-2.5.1-src# pushd ambari-metrics
/usr/local/ambari/apache-ambari-2.5.1-src/ambari-metrics /usr/local/ambari/apache-ambari-2.5.1-src
root@Ubuntu-04:/usr/local/ambari/apache-ambari-2.5.1-src/ambari-metrics# mvn versions:set -DnewVersion=2.5.1.0.0
root@Ubuntu-04:/usr/local/ambari/apache-ambari-2.5.1-src/ambari-metrics# popd
/usr/local/ambari/apache-ambari-2.5.1-src
root@Ubuntu-04:/usr/local/ambari/apache-ambari-2.5.1-src# mvn -B clean install package jdeb:jdeb -DnewVersion=2.5.1.0.0 -DskipTests -Dpython.ver="python >= 2.6"
# 如果遇到某些包因为墙的原因无法下载,则直接在网上下载对应的包放到日志指定的目录。
# 如果报错:ENOGIT git is not installed or not in the PATH,则安装git:apt-get install git。
# 如果遇到类似于下面的错误,则在对应项目的pom.xml中增加
<plugin>
<groupId>org.vafer</groupId>
<artifactId>jdeb</artifactId>
<version>1.0.1</version>
<executions>
<execution>
<!--Stub execution on direct plugin call - workaround for ambari deb build process-->
<id>stub-execution</id>
<phase>none</phase>
<goals>
<goal>jdeb</goal>
</goals>
</execution>
</executions>
<configuration>
<skip>true</skip>
<attach>false</attach>
<submodules>false</submodules>
<controlDir>${project.basedir}/../src/main/package/deb/control</controlDir>
</configuration>
</plugin>\
[ERROR] Failed to execute goal org.vafer:jdeb:1.0.1:jdeb (default-cli) on project ambari-logsearch: Failed to create debian package /home/kylin/apache-ambari-2.4.2-src/ambari-logsearch/target/ambari-logsearch_2.4.2.0.0_all.deb: “/home/kylin/apache-ambari-2.4.2-src/ambari-logsearch/src/main/package/deb/control” is not a valid ‘control’ directory) -> [Help 1]
# 如果遇到类似下面的错误,将对应项目的pom.xml中的storm版本改为1.1.0
<properties>
<storm.version>1.1.0 </storm.version>
</properties>
# 如果遇到如下报错,执行sudo apt-get install python-dev
[exec] creating build/temp.linux-x86_64-2.7/psutil
[exec] x86_64-linux-gnu-gcc -pthread -DNDEBUG -g -fwrapv -O2 -Wall -Wstrict-prototypes -fno-strict-aliasing -Wdate-time -D_FORTIFY_SOURCE=2 -g -fstack-protector-strong -Wformat -Werror=format-security -fPIC -I/usr/include/python2.7 -c psutil/_psutil_linux.c -o build/temp.linux-x86_64-2.7/psutil/_psutil_linux.o
[exec] psutil/_psutil_linux.c:12:20: fatal error: Python.h: 没有那个文件或目录
[exec] compilation terminated.
[exec] error: command 'x86_64-linux-gnu-gcc' failed with exit status 1
# 如果报如下错误,参考https://cwiki.apache.org//confluence/display/MAVEN/OutOfMemoryError
[ERROR] Java heap space -> [Help 1]
[ERROR]
[ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch.
[ERROR] Re-run Maven using the -X switch to enable full debug logging.
[ERROR]
[ERROR] For more information about the errors and possible solutions, please read the following articles:
[ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/OutOfMemoryError
大数据平台-kerberos安装部署文档
环境准备
操作系统
本次安装部署要求在操作系统为CentOS release 6.5 (Final)的版本下进行部署,所以在安装部署kerberos之前请先确保操作系统为以上版本,并且集群中各机器已做时钟同步。 本次安装部署以csdm-hadoop-04作为主kdc服务器,以csdm-hadoop-05作为从kdc服务器,以csdm-hadoop-03作为客户端。一般不建议在服务器上再安装其他应用程序,比如hadoop。但为了节省资源本次安装在这三台机器均已安装hadoop相关软件。
创建操作用户
创建操作系统hdfs、yarn、mapred用户,并使其归属于hadoop用户组: adduser hdfs -g Hadoop adduser yarn -g Hadoop adduser mapred -g Hadoop
配置hosts文件
为各台机器修改/etc/hosts文件,将真实ip与主机名对应配置,服务端与客户端均需配置,形如:(不能存在127.0.0.1的配置,否则hadoop进行kerberos验证时将会出错)

关闭防火墙
执行以下命令关闭防火墙:
service iptables stop
出现以下界面表示关闭成功

注册服务与端口的对应
在/etc/service文件最后增加以下信息,以便后续使用: krb5_prop 754/tcp # Kerberos slave propagation
安装配置Kerberos
安装rpm包
以root用户登录并创建目录存放安装包:
mkdir /var/kerberos
上传安装包文件到创建的目录,包括krb5-libs-1.10.3-10.el6_4.6.x86_64.rpm、krb5-server-1.10.3-10.el6_4.6.x86_64.rpm(客户端可不安装)、krb5-workstation-1.10.3-10.el6_4.6.x86_64.rpm
执行安装命令:
rpm -ivh krb5-libs-1.10.3-10.el6_4.6.x86_64.rpm
rpm -ivh krb5-server-1.10.3-10.el6_4.6.x86_64.rpm【客户端可不安装】
rpm -ivh krb5-workstation-1.10.3-10.el6_4.6.x86_64.rpm
查看上述包是否已安装成功:
rpm –qa krb5*
若出现以下情况则代表安装成功。
配置主KDC服务器
设置全局环境变量
需要以root身份登录系统在/etc/profile末尾增加配置文件的全局环境变量: export KRB5_CONFIG=/etc/krb5.conf export KRB5_KDC_PROFILE=/var/kerberos/krb5kdc/kdc.conf
保存后并 执行source /etc/profile 使之生效。
配置krb5.conf
执行vi编辑/etc/krb5.conf,内容如下:
[libdefaults] default_realm = ERICSSON.COM dns_lookup_realm = false dns_lookup_kdc = false ticket_lifetime = 24h renew_lifetime = 7d forwardable = true
[realms] ERICSSON.COM = { kdc = csdm-hadoop-04 kdc = csdm-hadoop-05 admin_server =csdm-hadoop-04 }
[domain_realm] .ericsson.com = ERICSSON.COM ericsson.com = ERICSSON.COM
配置kdc.conf
执行vi编辑/var/kerberos/krb5kdc/kdc.conf,内容如下: [kdcdefaults] Kdc_ports=750,88
[realms]
ERICSSON.COM ={
kadmind_port = 749
max_life=10h 0m 0s
max_renewable_life=7d 0h 0m 0s
database_name= /var/kerberos/krb5kdc/principal
admin_keytab=/var/kerberos /krb5kdc/kadm5.keytab
acl_file=/var/kerberos /krb5kdc/kadm5.acl
key_stash_file=/var/kerberos /krb5kdc/.k5.ERICSSON.COM
}
[logging]
default = FILE:/var/log/krb5libs.log
kdc = FILE:/var/log/krb5kdc.log
admin_server = FILE:/var/log/kadmind.log
集群机器如果开启selinux,请在机器上执行restorecon -R -v /etc/krb5.conf
生成数据库
在主KDC服务器上执行以下命令创建数据库,在执行的过程中会提示输入密码和确认密码,两次输入相同的密码即可: kdb5_util create -r ericsson.com –s
等待片刻后在提示输入密码界面输入密码后会出现以下界面:
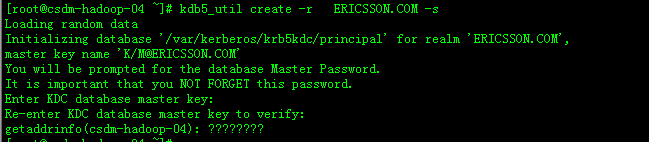
创建管理用户
运行管理入口命令: kadmin.local 在提示符下执行以下命令 addprinc kadmin/admin@ERICSSON.COM addprinc kadmin/changepw@ERICSSON.COM 会提示输入密码,输入两次一样的密码后会提示成功创建。
 将主体添加至密钥文件中
ktadd -k /var/kerberos/krb5kdc/kadm5.keytab kadmin/admin
ktadd -k /var/kerberos/krb5kdc/kadm5.keytab kadmin/changepw
将主体添加至密钥文件中
ktadd -k /var/kerberos/krb5kdc/kadm5.keytab kadmin/admin
ktadd -k /var/kerberos/krb5kdc/kadm5.keytab kadmin/changepw
启动krb5kdc 和kadmind服务
执行以下命令启动krb5kdc和kadmind服务:
krb5kdc start
kadmind
出现以下界面表示启动成功
配置从KDC服务器
为从kdc服务器创建创建授权票证
每一个kdc服务器都需要一个host票证,用于在迁移数据库数据市在各kdc服务器之间进行交互验证。注意,创建host票据需要在主kdc服务器上执行而不是在从kdc服务器。在csdm-hadoop-04上执行以下命令创建票证:
kadmin addprinc –randkey host/csdm-hadoop-04@ERICSSON.COM addprinc –randkey host/csdm-hadoop-05@ERICSSON.COM ktadd host/csdm-hadoop-05@ERICSSON.COM
设置从kdc服务器的配置文件
将主kdc服务器中的配置文件(kdc.conf、 krb5.conf、 .k5.ERICSSON.COM、 kadm5.acl)复制到从kdc服务器上相应的目录中;在从kdc服务器的/var/Kerberos/krb5kdc的目录下创建kpropd.acl文件并增加以下信息:
host/csdm-hadoop-04@ERICSSON.COM host/csdm-hadoop-05@ERICSSON.COM
复制数据库数据到KDC从服务器
在主服务器上创建数据库的dump文件 kdb5_util dump /var/kerberos/krb5kdc/slave_datatrans 在从服务器上执行数据迁移 kprop -f /var/Kerberos/krb5kdc/slave_datatrans csdm-hadoop-05
定时将主KDC服务器上的数据库数据,更新到从KDC服务器上
由于KDC不提供数据库数据的同步服务功能,因此需要使用脚本或者手工将主KDC服务器上的数据同步到从KDC服务器上,可以参考以下脚本,并配置到定时器中
#!/bin/sh
kdclist = “kerberos2.example.com kerberos3.example.com”
kdb5_util dump /var/kerberos/krb5kdc/slave_datatrans
for kdc in $kdclist do
kprop -f /var/kerberos/krb5kdc/slave_datatrans $kdc
启动从服务器的krb5kdc程序
在从服务器上启动命令执行启动: krb5kdc
配置自启动
在/etc/inittab中增加以下信息可使进程随系统自启动: /etc/init.d/krb5kdc start Kadmind
客户端配置
下面以csdm-hadoop-03这台机器作为客户端说明相关配置 1、在csdm-hadoop-03上安装客户端软件 rpm -ivh krb5-libs-1.10.3-10.el6_4.6.x86_64.rpm rpm -ivh krb5-workstation-1.10.3-10.el6_4.6.x86_64.rpm 2、在主KDC服务器csdm-hadoop-04上,把/etc/krb5.conf复制到csdm-hadoop-03本地对应目录 3、在客户端csdm-hadoop-03上启动命令执行启动: krb5kdc 此时即可在客户端csdm-hadoop-03上连接KDC服务器
4、生成可访问csdm-hadoop-03机器应用程序的验证 在主KDC服务器csdm-hadoop-04,生成csdm-hadoop-03的principals和keytab, 为客户端csdm-hadoop-03添加principals(可以为host或者所要进行验证的机器用户) addprinc –randkey host/csdm-hadoop-03@ERICSSON.COM 为客户端csdm-hadoop-03生成keytab Ktadd –k /var/kerberos/krb5kdc/keytab/host.keytab host/csdm-hadoop-03@ERICSSON.COM 把csdm-hadoop-04上生成的keytab复制到csdm-hadoop-03机器上
测试服务器
服务器端测试客户端连接
运行kinit admin/admin,显示提示输入密码则代表配置成功:
远程客户机连接测试
在客户机运行kinit admin/admin 连接服务端,显示提示输入密码则代表配置成功: 
Hadoop集成kerberos配置
4.1 kerberos配置
Hadoop官方网站建议的操作系统用户及权限如下,下面我们按照这三个用户的权限进行配置,要求使用下面三种用户分别具有各自启动相应进程的权限。 User:Group Daemons hdfs:hadoop NameNode, Secondary NameNode, JournalNode, DataNode yarn:hadoop ResourceManager, NodeManager mapred:hadoop MapReduce,JobHistory Server
4.1.1 为所有机器的用户生成principal
从主KDC服务器csdm-hadoop-04上,把/etc/krb5.conf复制到csdm-hadoop-03本地对应目录, 在主KDC服务器上为hadoop集群中每台机器的用户创建principal,下面以csdm-hadoop-03这台机器为例,运行管理入口命令: kadmin.local 在提示符下执行以下命令: addprinc -randkey hdfs/csdm-hadoop-03@ERICSSON.COM addprinc -randkey host/csdm-hadoop-03@ERICSSON.COM
addprinc -randkey yarn/csdm-hadoop-03@ERICSSON.COM addprinc -randkey host/csdm-hadoop-03@ERICSSON.COM
addprinc -randkey mapred/csdm-hadoop-03@ERICSSON.COM addprinc -randkey host/csdm-hadoop-03@ERICSSON.COM
注: 集群中的每台机器所用到的用户都需执行上面的命令生成principal 每个用户必须执行addprinc -randkey host/XX@XX的命令,这个命令生成的是基于 Kerberos 的应用程序(例如 klist 和 kprop)和服务(例如 ftp 和 telnet)使用的主体。此主体称为 host 主体或服务主体。
4.1.2 生成keytab文件
完成5.1.1后在主KDC服务器上为所有principal生成keytab文件,运行管理入口命令: kadmin.local 在提示符下执行以下命令: xst -norandkey -k /var/kerberos/krb5kdc/keytab/hdfs.keytab hdfs/csdm-hadoop-03@ERICSSON.COM host/csdm-hadoop-03@ERICSSON.COM xst -norandkey -k /var/kerberos/krb5kdc/keytab/mapred.keytab mapred/csdm-hadoop-03@ ERICSSON.COM host/csdm-hadoop-03@ERICSSON.COM xst -norandkey -k /var/kerberos/krb5kdc/keytab/yarn.keytab yarn/csdm-hadoop-03@ERICSSON.COM host/csdm-hadoop-03@ERICSSON.COM
生成授权文件后,使用以下命令检查生成的keytab是否可用: kinit -k -t /var/kerberos/krb5kdc/keytab/hdfs.keytab hdfs/csdm-hadoop-03@ERICSSON.COM kinit -k -t /var/kerberos/krb5kdc/keytab/mapred.keytab mapred/csdm-hadoop-03@ERICSSON.COM kinit -k -t /var/kerberos/krb5kdc/keytab/yarn.keytab yarn/csdm-hadoop-03@ERICSSON.COM
检查没问题后,把生成的keytab文件分发到整个集群中的所有机器。
修改HADOOP配置文件
4.2.1 Jsvc安装配置
Datanode的安全机制需要以root用户身份用jsvc来启动,因此首先需要检查是否安装是jsvc如果没有,按以下步骤进行安装: 1、 下载commons-daemon-1.0.15-src.tar.gz 包并上传至自定义的目录(本操作目录为/home/hadoop) 2、 解压缩后 以root用户登录进入目录/home/Hadoop 执行: tar –xvf commons-daemon-1.0.15-bin.tar.gz 解压完成后进入 /home/Hadoop /commons-daemon-1.0.15-src/src/native/unix 执行命令:configure 执行命令:make 编译完成后,会在/home/hadoop/commons-daemon-1.0.15-src/src/native/unix目录下生成jsvc可执行文件,如下图

在该目录下执行file jsvc如果出现下图所示,则jsvc安装成功

这里,我们把该执行文件复制到$HADOOP_HOME/bin以便后续的配置
执行命令:cp /home/hadoop/commons-daemon-1.0.15-src/src/native/unix/jsvc
/home/hadoop/hadoop/bin

4.2.2 hadoop-env.sh配置
找到以下两项配置,并修改 export HADOOP_SECURE_DN_USER=hdfs(配置为要执行datanode的用户,这里为hdfs) export JSVC_HOME=/home/hadoop/hadoop/bin(配置为jsvc所在的目录)
4.2.3 core-site.xml
在集群中所有节点的core-site.xml文件中添加下面的配置
<!-- kerberos config -->
<property>
<name>hadoop.security.authorization</name>
<value>true</value>
</property>
<property>
<name>hadoop.security.authentication</name>
<value>kerberos</value>
</property>
<property>
<name>hadoop.rpc.protection</name>
<value>authentication</value>
</property><!—默认使用authentication,可使用integrity ,privacy -->
<property>
<name> hadoop.security.auth_to_local</name>
<value> DEFAULT</value>
</property><!—此选项对应krb5.conf中【realms】的auth_to_local,用于将操作系统用户与principal 的映射关系-->
4.2.4 hdfs-site.xml
在集群中所有节点的hdfs-site.xml文件中添加下面的配置,下面配置以节点csdm-hadoop-04为例:
配置中有几点要注意的 . dfs.datanode.address表示data transceiver RPC server所绑定的hostname或IP地址,如果开启security,端口号必须小于1024(privileged port),否则的话启动datanode时候会报“Cannot start secure cluster without privileged resources”错误 . principal中的instance部分可以使用’_HOST’标记,系统会自动替换它为全称域名 . 如果开启了security, hadoop会对hdfs block data做permission check,方式用户的代码不是调用hdfs api而是直接本地读block data,这样就绕过了kerberos和文件权限验证,管理员可以通过设置dfs.datanode.data.dir.perm来修改datanode文件权限,这里我们设置为700
配置完成后,修改hdfs.keytab所有者为hdfs chown -R hdfs:hadoop /var/kerberos/krb5kdc/keytab/hdfs.keytab chmod 700 /var/kerberos/krb5kdc/keytab/hdfs.keytab
同时保证以下表格中各个目录的对于hdfs用户的权限
Filesystem Path User:Group Permissions local dfs.namenode.name.dir hdfs:hadoop drwx—— local dfs.datanode.data.dir hdfs:hadoop drwx—— local $HADOOP_LOG_DIR hdfs:hadoop drwxrwxr-x Hdfs / hdfs:hadoop drwxr-xr-x Hdfs /tmp hdfs:hadoop drwxrwxrwxt Hdfs /user hdfs:hadoop drwxr-xr-x
1、测试namenode进程启动是否正常
切换到hdfs用户,首先执行klist命令,查看当前是否获取了ticket,经测试,如果已经获取了ticket那么启动namenode进程的时候会报以下错误
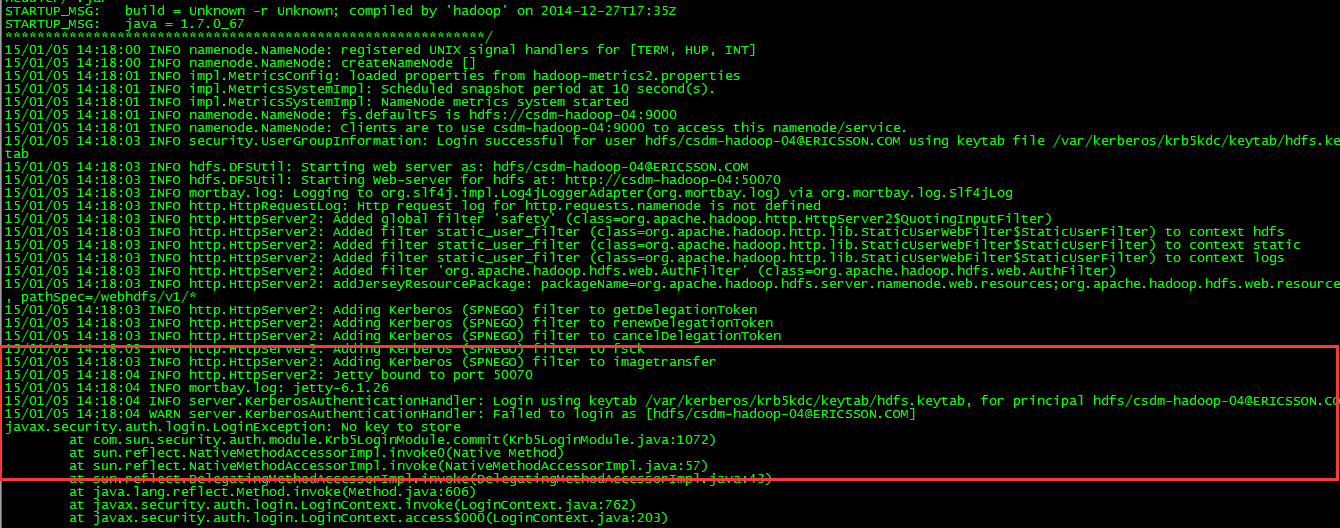 使用kdestroy销毁获取的ticket
使用kdestroy销毁获取的ticket

切换到hdfs用户,启动namenode进程(已经执行过HDFS格式化的操作)
执行命令:hadoop namenode
 如果配置正常,应该会看到以下的日志信息输出
如果配置正常,应该会看到以下的日志信息输出
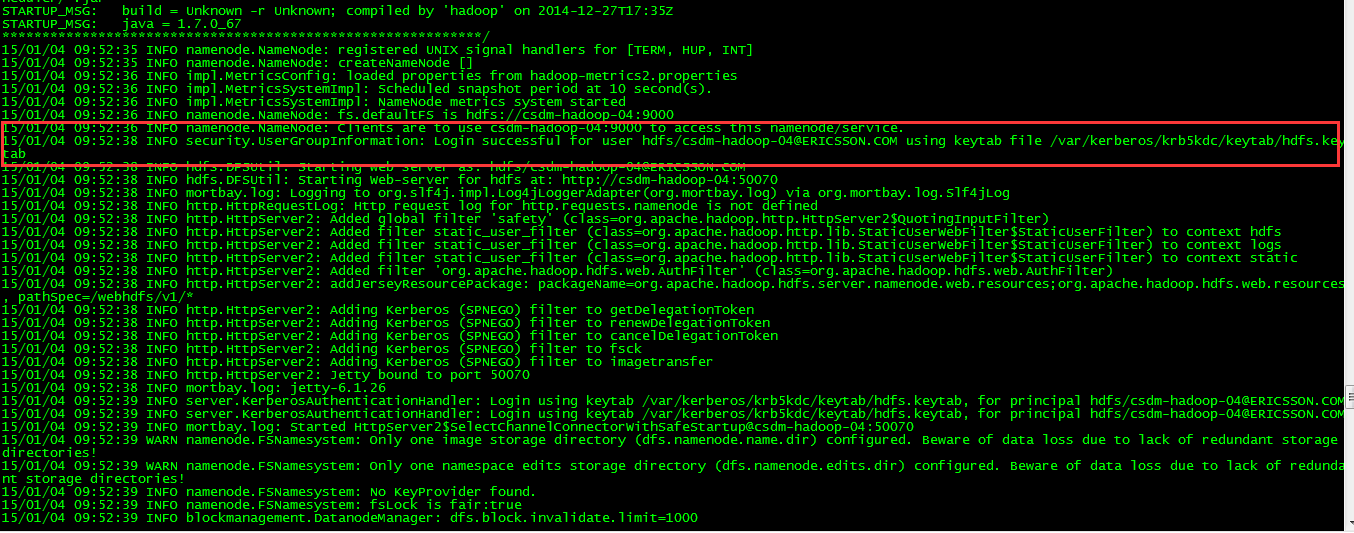
验证namenode是否启动正常
可打开网页
http://XX:50070/dfshealth.html#tab-overview验证
hadoop fs -ls /
注:如果在你的凭据缓存中没有有效的kerberos ticket,执行hadoop fs –ls /将会失败。
可以使用klist来查看是否有有有效的ticket。
 如果为空,使用kinit来获取ticket.命令如下
kinit -k -t /var/kerberos/krb5kdc/keytab/hdfs.keytab hdfs/csdm-hadoop-03@ERICSSON.COM
如果为空,使用kinit来获取ticket.命令如下
kinit -k -t /var/kerberos/krb5kdc/keytab/hdfs.keytab hdfs/csdm-hadoop-03@ERICSSON.COM
2、测试datanode启动是否正常
切换到root用户,
执行命令:hadoop-daemon.sh start datanode
 如果启动正常,能在日志文件看到以下日志内容
如果启动正常,能在日志文件看到以下日志内容
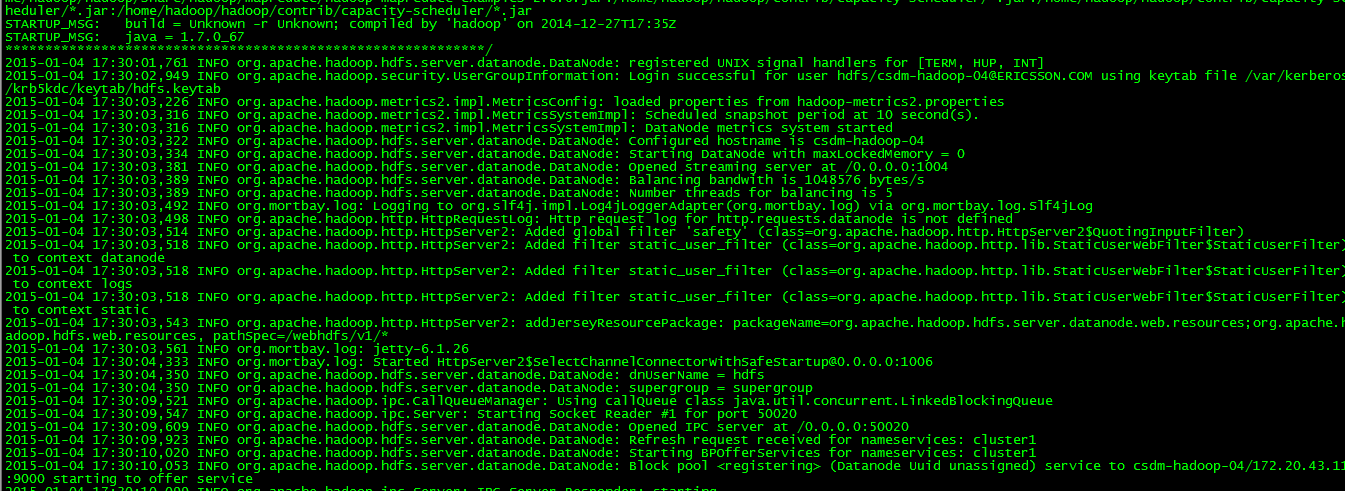 在日志目录,启动datanode进程会有以下几个日志文件,其中jsvc.err记录了jsvc的错误信息
在日志目录,启动datanode进程会有以下几个日志文件,其中jsvc.err记录了jsvc的错误信息
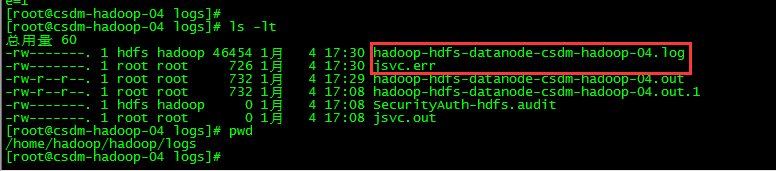
启动datanode进程,只能使用root用户,如果使用其他用户启动,只会报以下错误
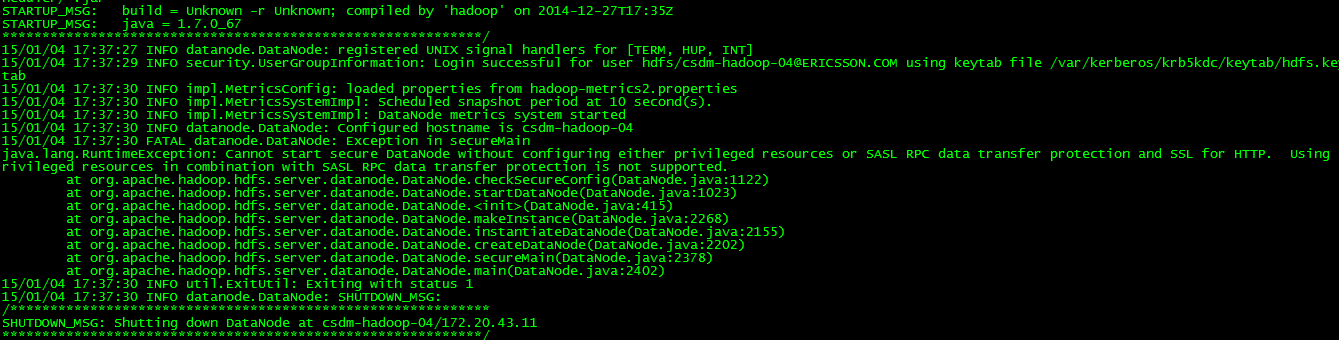
4.2.5 mapred-site.xml
在mapred-site.xml中添加
将mapred.keytab文件赋权给mapred用户 ,执行以下命令: chown -R mapred:hadoop /var/kerberos/krb5kdc/keytab/mapred.keytab chmod 700 /var/kerberos/krb5kdc/keytab/mapred.keytab 确保以下表格中各个路径的执行权限 Filesystem Path User:Group Permissions hdfs mapreduce.jobhistory.intermediate-done-dir mapred:hadoop drwxrwxrwxt hdfs mapreduce.jobhistory.done-dir mapred:hadoop drwxr-x—
测试historyserver 进程
执行命令:mr-jobhistory-daemon.sh start historyserver
配置正常,则会看到以下日志内容
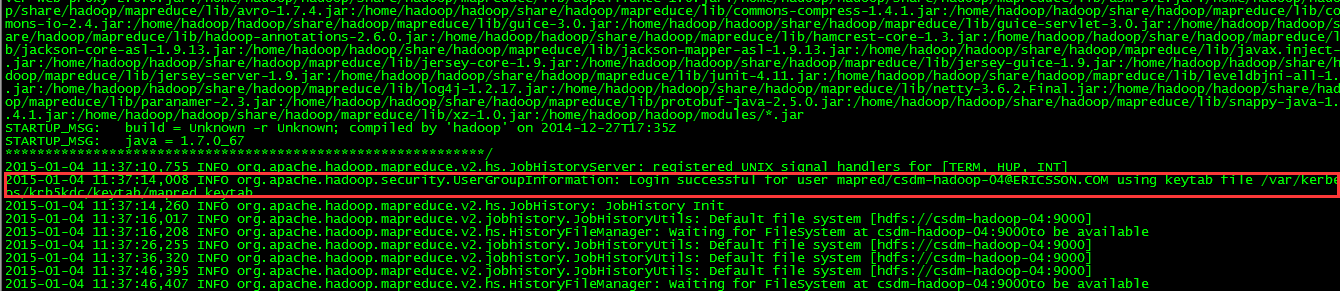
4.2.6 yarn-site.xml
在yarn-site.xml追加以下内容:
<!—以上为NodeManager配置-->
YARN提供了两种Container启动实现,DefaultContainerExecutor以及LinuxContainerExecutor,在上面的yarn-site.xml里配置了yarn.nodemanager.container-executor.class的启动方式为LinuxContainerExecutor,那么就需要编译安装LinuxContainerExecutor,按如下操作执行:在hadoop的home目录(这里是/home/Hadoop/hadoop)的 /etc/hadoop/目录下创建 container-executor.cfg 文件,内容如下:

设置该文件权限:
$ chown root:hadoop container-executor.cfg
$ chmod 400 container-executor.cfg
 注意:
• container-executor.cfg 文件读写权限需设置为 400,所有者为 root:hadoop。
并且该文件所在的父目录所有者必须为root用户,并对该文件所在的各个父目录赋以下权限,例如:chmod 750 /home/hadoop/
• yarn.nodemanager.linux-container-executor.group 要同时配置在 yarn-site.xml 和 container-executor.cfg,且其值需要为运行 NodeManager 的用户所在的组,这里为 hadoop。
• banned.users 不能为空,默认值为 hfds,yarn,mapred,bin
• min.user.id 默认值为 1000,在centos系统中,需要设置为小于500的值
• 确保 yarn.nodemanager.local-dirs 和 yarn.nodemanager.log-dirs 对应的目录权限为 755 。
设置 $HADOOP_HOME/bin/container-executor 读写权限为 6050 如下:
$ chown root:hadoop $HADOOP_HOME/bin/container-executor
$ chmod 6050 $HADOOP_HOME/bin/container-executor
注意:
• container-executor.cfg 文件读写权限需设置为 400,所有者为 root:hadoop。
并且该文件所在的父目录所有者必须为root用户,并对该文件所在的各个父目录赋以下权限,例如:chmod 750 /home/hadoop/
• yarn.nodemanager.linux-container-executor.group 要同时配置在 yarn-site.xml 和 container-executor.cfg,且其值需要为运行 NodeManager 的用户所在的组,这里为 hadoop。
• banned.users 不能为空,默认值为 hfds,yarn,mapred,bin
• min.user.id 默认值为 1000,在centos系统中,需要设置为小于500的值
• 确保 yarn.nodemanager.local-dirs 和 yarn.nodemanager.log-dirs 对应的目录权限为 755 。
设置 $HADOOP_HOME/bin/container-executor 读写权限为 6050 如下:
$ chown root:hadoop $HADOOP_HOME/bin/container-executor
$ chmod 6050 $HADOOP_HOME/bin/container-executor
 测试是否配置正确:
$ /home/hadoop/hadoop/bin/container-executor –checksetup
出现以下信息,则表示配置正确,如果出错,请检查各个目录的权限及container-executor.cfg文件是否配置正确
测试是否配置正确:
$ /home/hadoop/hadoop/bin/container-executor –checksetup
出现以下信息,则表示配置正确,如果出错,请检查各个目录的权限及container-executor.cfg文件是否配置正确

修改yarn.keytab权限 chown -R yarn:hadoop /var/kerberos/krb5kdc/keytab/ yarn.keytab chmod 700 /var/kerberos/krb5kdc/keytab/yarn.keytab
确保以下表格各目录的权限 Filesystem Path User:Group Permissions hdfs yarn.nodemanager.remote-app-log-dir yarn:hadoop drwxrwxrwxt local $YARN_LOG_DIR yarn:hadoop drwxrwxr-x local yarn.nodemanager.local-dirs yarn:hadoop drwxr-xr-x local yarn.nodemanager.log-dirs yarn:hadoop drwxr-xr-x local container-executor root:hadoop –Sr-s— local conf/container-executor.cfg root:hadoop r——–
测试 nodemanager 进程
执行命令:yarn nodemanager
 如果配置正常,会输出以下日志
如果配置正常,会输出以下日志
测试resourcemanager进程
执行命令:yarn resourcemanager
 如果配置正常,会输出以下日志
如果配置正常,会输出以下日志
说明
注:本部署文档部署环境默认机器未配置DNS,如果配置有DNS的机器上创建实体则格式为:用户名/hostname.DNS@领域名。例如:hdfs/csdm-hadoop-04.ericsson.com@ERICSSON.COM
火狐配置使用SPNNEGO 1、 在地址栏输入about:config打开配置界面 2、 network.negotiate-auth.delegation-uris network.negotiate-auth.trusted-uris 找到以上两个选项,把你要访问的页面地址加进去
LINUX下配置
1、 在/etc/hosts下加入要访问的地址对应关系(包括客户端和服务器)
2、 在KDC服务器上生成浏览器所在客户端的principal:格式如下:HTTP/hd2@ERICSSON.COM,并把该principal生成到keytab中,在KEYTAB中应该可以看到如下的信息
Ubuntu 16.04安装DB2 Express C v11.1
jiangxin@db01:~$ su – root #切换到root用户
密码:
root@db01:~# uname -a #查看内核和操作系统信息
Linux db01 4.4.0-66-generic #87-Ubuntu SMP Fri Mar 3 15:29:05 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
root@db01:~# head -n 1 /etc/issue #查看Linux发行版信息
Ubuntu 16.04.1 LTS \n \l
root@db01:~# cd /usr/local
root@db01:/usr/local# ls
bin db2 etc games include java lib man sbin scala share src
root@db01:/usr/local# mkdir db2
root@db01:/usr/local# cd db2/
#上传安装包
root@db01:/usr/local/db2# ll
总用量 675924
drwxrwxrwx 2 root root 4096 3月 17 22:08 ./
drwxr-xr-x 20 root root 4096 3月 17 22:07 ../
-rw-rw-r-- 1 root root 692132552 3月 17 22:08 v11.1_linuxx64_expc.tar.gz
root@db01:/usr/local/db2# tar -zxvf v11.1_linuxx64_expc.tar.gz
root@db01:/usr/local/db2# cd expc/
root@db01:/usr/local/db2/expc# ls
db2 db2ckupgrade db2_deinstall db2_install db2ls db2prereqcheck db2setup
root@db01:/usr/local/db2/expc# ./db2prereqcheck #检查是否满足安装条件
==========================================================================
正在检查操作系统 "Linux" V"11.1.1.1" 的 DB2 安装的先决条件。
正在验证 "Linux 分发 " ...
要求的最低 "UBUNTU" 版本:"14.04"
实际版本:"16.04"
达到要求。
正在验证 "内核级别 " ...
要求的最低操作系统内核级别:"2.6.16"。
实际操作系统内核级别:"4.4.0"。
达到要求。
正在验证 "C++ 库版本 " ...
要求的最低 C++ 库版本:"libstdc++.so.6"
标准 C++ 库位于以下目录中:"/usr/lib/x86_64-linux-gnu/libstdc++.so.6.0.21"。
实际 C++ 库:"CXXABI_1.3.1"
达到要求。
正在验证 ""libstdc++.so.6" 的 32 位版本 " ...
在以下目录中找到了 64 位 "/usr/lib/x86_64-linux-gnu/libstdc++.so.6":"/usr/lib/x86_64-linux-gnu"。
在以下目录中找到了 32 位 "/usr/lib32/libstdc++.so.6":"/usr/lib32"。
达到要求。
正在验证 "libaio.so 版本 " ...
DBT3553I db2prereqcheck 实用程序已成功装入 libaio.so.1 文件。
达到要求。
正在验证 "Unable to find the string resource 30186" ...
Unable to find the string resource 33610
达到要求。
正在验证 "/lib/i386-linux-gnu/libpam.so*" ...
达到要求。
DBT3533I db2prereqcheck 实用程序已确认所有安装先决条件均已满足。
#限于篇幅,此处省略部分内容
DBT3533I db2prereqcheck 实用程序已确认所有安装先决条件均已满足。
DBT3555E db2prereqcheck 实用程序已确定,以下版本不支持当前平台:"9.8.0.4"。
DBT3555E db2prereqcheck 实用程序已确定,以下版本不支持当前平台:"9.8.0.3"。
DBT3555E db2prereqcheck 实用程序已确定,以下版本不支持当前平台:"9.8.0.2"。
#如果之前的检查中存在某些不满足项,可以通过下面的命令安装对应库文件
root@db01:/usr/local/db2/expc# apt-get install lib32stdc++6
root@db01:/usr/local/db2/expc# apt-get install libaio1
root@db01:/usr/local/db2/expc# apt-get install libpam0g:i386
root@db01:/usr/local/db2/expc# ./db2_install #开始正式安装
阅读 CD 上 db2/license 目录中的许可协议文件。
***********************************************************
要接受这些条款,请输入 "yes"。否则,输入 "no" 以取消安装过程。[yes/no]
yes
产品的缺省安装目录 - /opt/ibm/db2/V11.1
***********************************************************
是否安装至缺省目录 (/opt/ibm/db2/V11.1)?[yes/no]
yes
正在初始化 DB2 安装。
要执行的任务总数为:36
要执行的所有任务的总估计时间为:1591 秒
任务 #1 启动
描述:正在检查许可协议的接受情况
估计时间 1 秒
任务 #1 结束
任务 #2 启动
描述:具备 root 用户特权的情况下进行安装时的基本客户机支持
估计时间 3 秒
任务 #2 结束
任务 #3 启动
描述:产品消息 - 英语
估计时间 14 秒
任务 #3 结束
任务 #4 启动
描述:基本客户机支持
估计时间 352 秒
任务 #4 结束
任务 #5 启动
描述:Java 运行时支持
估计时间 188 秒
任务 #5 结束
任务 #6 启动
描述:Java 帮助 (HTML) - 英语
估计时间 7 秒
任务 #6 结束
任务 #7 启动
描述:具备 root 用户特权的情况下进行安装时的基本服务器支持
估计时间 8 秒
任务 #7 结束
任务 #8 启动
描述:全局安全工具箱
估计时间 64 秒
任务 #8 结束
任务 #9 启动
描述:Java 支持
估计时间 13 秒
任务 #9 结束
任务 #10 启动
描述:SQL 过程
估计时间 3 秒
任务 #10 结束
任务 #11 启动
描述:ICU 实用程序
估计时间 34 秒
任务 #11 结束
任务 #12 启动
描述:Java 公共文件
估计时间 18 秒
任务 #12 结束
任务 #13 启动
描述:基本服务器支持
估计时间 577 秒
任务 #13 结束
任务 #14 启动
描述:DB2 数据源支持
估计时间 6 秒
任务 #14 结束
任务 #15 启动
描述:Spatial Extender 服务器支持
估计时间 18 秒
任务 #15 结束
任务 #16 启动
描述:DB2 LDAP 支持
估计时间 4 秒
任务 #16 结束
任务 #17 启动
描述:“DB2 实例安装”向导
估计时间 25 秒
任务 #17 结束
任务 #18 启动
描述:集成动漫复制支持
估计时间 3 秒
任务 #18 结束
任务 #19 启动
描述:Spatial Extender 客户机
估计时间 3 秒
任务 #19 结束
任务 #20 启动
描述:通信支持 - TCP/IP
估计时间 3 秒
任务 #20 结束
任务 #21 启动
描述:基本应用程序开发工具
估计时间 35 秒
任务 #21 结束
任务 #22 启动
描述:DB2 更新服务
估计时间 4 秒
任务 #22 结束
任务 #23 启动
描述:EnterpriseDB 代码
估计时间 4 秒
任务 #23 结束
任务 #24 启动
描述:样本数据库源
估计时间 4 秒
任务 #24 结束
任务 #25 启动
描述:DB2 Text Search
估计时间 123 秒
任务 #25 结束
任务 #26 启动
描述:命令行处理器加强版
估计时间 6 秒
任务 #26 结束
任务 #27 启动
描述:第一步
估计时间 3 秒
任务 #27 结束
任务 #28 启动
描述:DB2 Express-C 的产品特征符
估计时间 3 秒
任务 #28 结束
任务 #29 启动
描述:正在设置 DB2 库路径
估计时间 180 秒
任务 #29 结束
任务 #30 启动
描述:正在执行控制任务
估计时间 20 秒
任务 #30 结束
任务 #31 启动
描述:正在更新全局注册表
估计时间 20 秒
任务 #31 结束
任务 #32 启动
描述:正在启动 DB2 故障监视器
估计时间 10 秒
任务 #32 结束
任务 #33 启动
描述:正在更新 db2ls 和 db2greg 链接
估计时间 1 秒
任务 #33 结束
任务 #34 启动
描述:正在注册 DB2 许可证
估计时间 5 秒
任务 #34 结束
任务 #35 启动
描述:正在设置缺省全局概要文件注册表变量
估计时间 1 秒
任务 #35 结束
任务 #36 启动
描述:正在初始化实例列表
估计时间 5 秒
任务 #36 结束
任务 #37 启动
描述:正在注册 DB2 更新服务
估计时间 30 秒
任务 #37 结束
任务 #38 启动
描述:正在更新全局概要文件注册表
估计时间 3 秒
任务 #38 结束
已成功完成执行。
有关更多信息,请参阅 "/tmp/db2_install.log.5804" 上的 DB2
安装日志。
#创建实例前先创建对应的用户和组
root@db01:/usr/local/db2/expc# groupadd -g 2000 db2iadm1
root@db01:/usr/local/db2/expc# groupadd -g 2001 db2fadm1
root@db01:/usr/local/db2/expc# useradd -m -g db2iadm1 -d /home/db2inst1 db2inst1
root@db01:/usr/local/db2/expc# useradd -m -g db2fadm1 -d /home/db2fenc1 db2fenc1
root@db01:/usr/local/db2/expc# passwd db2inst1
输入新的 UNIX 密码:
重新输入新的 UNIX 密码:
passwd:已成功更新密码
root@db01:/usr/local/db2/expc# passwd db2fenc1
输入新的 UNIX 密码:
重新输入新的 UNIX 密码:
passwd:已成功更新密码
#安装License
root@db01:/usr/local/db2/expc# cd /opt/ibm/db2/V11.1/adm/
root@db01:/opt/ibm/db2/V11.1/adm# chmod -R 775 *
root@db01:/opt/ibm/db2/V11.1/adm# ./db2licm -a /usr/local/db2/expc/db2/license/db2expc_uw.lic
LIC1402I License added successfully.
LIC1426I This product is now licensed for use as outlined in your License Agreement. USE OF THE PRODUCT CONSTITUTES ACCEPTANCE OF THE TERMS OF THE IBM LICENSE AGREEMENT, LOCATED IN THE FOLLOWING DIRECTORY: "/opt/ibm/db2/V11.1/license/zh_CN.utf8"
# 创建实例
root@db01:/opt/ibm/db2/V11.1/adm# cd /opt/ibm/db2/V11.1/instance/
root@db01:/opt/ibm/db2/V11.1/instance# chmod -R 775 *
root@db01:/opt/ibm/db2/V11.1/instance# ./db2icrt -p 50000 -u db2fenc1 db2inst1
DBI1446I The db2icrt command is running.
DB2 installation is being initialized.
Total number of tasks to be performed: 4
Total estimated time for all tasks to be performed: 309 second(s)
Task #1 start
Description: Setting default global profile registry variables
Estimated time 1 second(s)
Task #1 end
Task #2 start
Description: Initializing instance list
Estimated time 5 second(s)
Task #2 end
Task #3 start
Description: Configuring DB2 instances
Estimated time 300 second(s)
Task #3 end
Task #4 start
Description: Updating global profile registry
Estimated time 3 second(s)
Task #4 end
The execution completed successfully.
For more information see the DB2 installation log at "/tmp/db2icrt.log.28370".
DBI1070I Program db2icrt completed successfully.
#创建样本数据库
root@db01:/opt/ibm/db2/V11.1/instance#
db2inst1@db01:~$ db2sampl
Starting the DB2 instance...
Creating database "SAMPLE"...
Connecting to database "SAMPLE"...
Creating tables and data in schema "DB2INST1"...
Creating tables with XML columns and XML data in schema "DB2INST1"...
Stopping the DB2 instance...
'db2sampl' processing complete.
db2inst1@db01:~$ db2start
SQL1063N DB2START processing was successful.
db2inst1@db01:~$ db2 connect to sample
Database Connection Information
Database server = DB2/LINUXX8664 11.1.1.1
SQL authorization ID = DB2INST1
Local database alias = SAMPLE
db2inst1@db01:~$ db2 "select * from staff"
ID NAME DEPT JOB YEARS SALARY COMM
------ --------- ------ ----- ------ --------- ---------
10 Sanders 20 Mgr 7 98357.50 -
20 Pernal 20 Sales 8 78171.25 612.45
30 Marenghi 38 Mgr 5 77506.75 -
40 O'Brien 38 Sales 6 78006.00 846.55
50 Hanes 15 Mgr 10 80659.80 -
60 Quigley 38 Sales - 66808.30 650.25
70 Rothman 15 Sales 7 76502.83 1152.00
80 James 20 Clerk - 43504.60 128.20
90 Koonitz 42 Sales 6 38001.75 1386.70
100 Plotz 42 Mgr 7 78352.80 -
110 Ngan 15 Clerk 5 42508.20 206.60
120 Naughton 38 Clerk - 42954.75 180.00
130 Yamaguchi 42 Clerk 6 40505.90 75.60
140 Fraye 51 Mgr 6 91150.00 -
150 Williams 51 Sales 6 79456.50 637.65
160 Molinare 10 Mgr 7 82959.20 -
170 Kermisch 15 Clerk 4 42258.50 110.10
180 Abrahams 38 Clerk 3 37009.75 236.50
190 Sneider 20 Clerk 8 34252.75 126.50
200 Scoutten 42 Clerk - 41508.60 84.20
210 Lu 10 Mgr 10 90010.00 -
220 Smith 51 Sales 7 87654.50 992.80
230 Lundquist 51 Clerk 3 83369.80 189.65
240 Daniels 10 Mgr 5 79260.25 -
250 Wheeler 51 Clerk 6 74460.00 513.30
260 Jones 10 Mgr 12 81234.00 -
270 Lea 66 Mgr 9 88555.50 -
280 Wilson 66 Sales 9 78674.50 811.50
290 Quill 84 Mgr 10 89818.00 -
300 Davis 84 Sales 5 65454.50 806.10
310 Graham 66 Sales 13 71000.00 200.30
320 Gonzales 66 Sales 4 76858.20 844.00
330 Burke 66 Clerk 1 49988.00 55.50
340 Edwards 84 Sales 7 67844.00 1285.00
350 Gafney 84 Clerk 5 43030.50 188.00
35 record(s) selected.
#安装DAS。为了远程客户端能够用控制中心来控制数据库服务器,需要在数据库服务器上安装DAS,当然如果只是远程连接而不是远程管理,可以不用装
db2inst1@db01:~$ exit
注销
root@db01:/opt/ibm/db2/V11.1/instance# groupadd -g 2002 db2asgrp
root@db01:/opt/ibm/db2/V11.1/instance# useradd -m -g db2asgrp -d /home/db2as db2as
root@db01:/opt/ibm/db2/V11.1/instance# passwd db2as
输入新的 UNIX 密码:
重新输入新的 UNIX 密码:
passwd:已成功更新密码
root@db01:/opt/ibm/db2/V11.1/instance# ./dascrt -u db2as
DBI1070I Program dascrt completed successfully.
root@db01:/opt/ibm/db2/V11.1/instance# su - db2as
db2as@db01:~$ db2admin start
SQL4409W The DB2 Administration Server is already active.
#确认db2inst1实例的服务名
db2as@db01:~$ su - db2inst1
密码:
db2inst1@db01:~$ db2 get dbm cfg|grep SVCENAME
TCP/IP Service name (SVCENAME) = 50000
SSL service name (SSL_SVCENAME) =
#如果SVCENAME显示为空,则执行下面的语句更新
db2inst1@db01:~$ db2 update dbm cfg using SVCENAME 50000
DB20000I The UPDATE DATABASE MANAGER CONFIGURATION command completed
successfully.
#看一下License的情况,svcename在客户端连接时需要用到
db2inst1@db01:~$ db2licm -l
Product name: "DB2 Express-C"
License type: "Unwarranted"
Expiry date: "Permanent"
Product identifier: "db2expc"
Version information: "11.1"
Max number of CPUs: "2"
Max amount of memory (GB): "16"
Enforcement policy: "Soft Stop"
Ubunut安装/卸载Mysql(apg-get方式)
安装
jiangxin@db01:~$ uname -a #查看内核和操作系统信息
Linux db01 4.4.0-66-generic #87-Ubuntu SMP Fri Mar 3 15:29:05 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux
jiangxin@db01:~$ head -n 1 /etc/issue #查看Linux发行版信息
Ubuntu 16.04.1 LTS \n \l
jiangxin@db01:~$ sudo netstat -tap | grep mysql #查看是否系统中已经安装mysql
jiangxin@db01:~$ sudo apt-get install mysql-server mysql-client libmysqlclient-dev
安装过程中会要求输入mysql的root账号密码,如下所示:
jiangxin@db01:~$ mysql -u root -p
Enter password:
Welcome to the MySQL monitor. Commands end with ; or \g.
Your MySQL connection id is 6
Server version: 5.7.17-0ubuntu0.16.04.1 (Ubuntu)
Copyright (c) 2000, 2016, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its
affiliates. Other names may be trademarks of their respective
owners.
Type 'help;' or '\h' for help. Type '\c' to clear the current input statement.
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.00 sec)
MySQL安装后的目录结构如下(此结构只针对于使用apt-get install 在线安装情况):
- 数据库存放目录: /var/lib/mysql/
- 相关配置文件存放目录: /usr/share/mysql
- 相关命令存放目录: /usr/bin(mysqladmin mysqldump等命令)
- 启动脚步存放目录: /etc/rc.d/init.d/
卸载
jiangxin@db01:~$ ps aux | grep mysql
mysql 1942 3.5 14.8 1115880 150404 ? Ssl 10:45 0:00 /usr/sbin/mysqld
jiangxin 1980 0.0 0.0 15984 948 pts/0 S+ 10:45 0:00 grep --color=auto mysql
jiangxin@db01:~$ mysqladmin -u root -p shutdown
Enter password:
jiangxin@db01:~$ ps aux | grep mysql
jiangxin 1984 0.0 0.0 15984 964 pts/0 S+ 10:46 0:00 grep --color=auto mysql
jiangxin@db01:~$ sudo apt-get autoremove --purge mysql-*
...
jiangxin@db01:~$ dpkg -l |grep ^rc|awk '{print $2}' |sudo xargs dpkg -P
...
jiangxin@db01:~$ su – root
root@db01:~# rm -rf /var/lib/mysql
root@db01:~# rm -rf /etc/mysql
MySQL简单管理
#启动MySQL服务
sudo service mysql start
#停止MySQL服务
sudo service mysql stop
#修改 MySQL 的管理员密码
sudo mysqladmin -u root password newpassword
#正常情况下,mysql占用的3306端口只是在IP 127.0.0.1上监听,拒绝了其他IP的访问。取消本地监听限制需要修改 mysqld.cnf 文件
sudo vi /etc/mysql/mysql.conf.d/mysqld.cnf
# 找到此内容并且注释
bind-address = 127.0.0.1
Windows 10安装MySQL5.5 安装
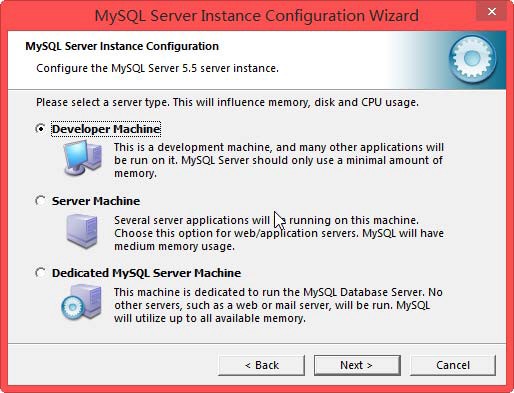
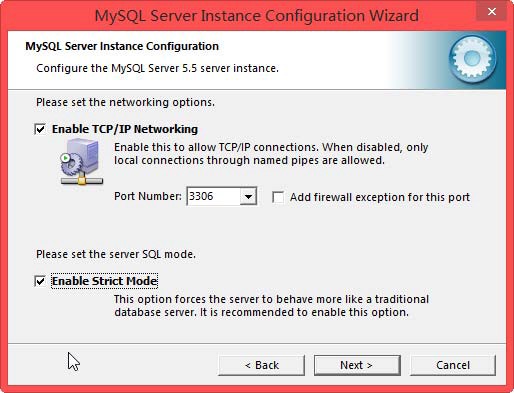
Ubuntu 16.04安装SQLLite3
jiangxin@db01:~$ sudo apt-get install sqlite3
[sudo] jiangxin 的密码:
正在读取软件包列表... 完成
正在分析软件包的依赖关系树
正在读取状态信息... 完成
建议安装:
sqlite3-doc
下列【新】软件包将被安装:
sqlite3
升级了 0 个软件包,新安装了 1 个软件包,要卸载 0 个软件包,有 244 个软件包未被升级。
需要下载 515 kB 的归档。
解压缩后会消耗 1,938 kB 的额外空间。
获取:1 http://cn.archive.ubuntu.com/ubuntu xenial/main amd64 sqlite3 amd64 3.11.0-1ubuntu1 [515 kB]
已下载 515 kB,耗时 0秒 (713 kB/s)
正在选中未选择的软件包 sqlite3。
(正在读取数据库 ... 系统当前共安装有 213307 个文件和目录。)
正准备解包 .../sqlite3_3.11.0-1ubuntu1_amd64.deb ...
正在解包 sqlite3 (3.11.0-1ubuntu1) ...
正在处理用于 man-db (2.7.5-1) 的触发器 ...
正在设置 sqlite3 (3.11.0-1ubuntu1) ...
jiangxin@db01:~$ sudo apt-get install sqlite3-doc
正在读取软件包列表... 完成
正在分析软件包的依赖关系树
正在读取状态信息... 完成
下列【新】软件包将被安装:
sqlite3-doc
升级了 0 个软件包,新安装了 1 个软件包,要卸载 0 个软件包,有 244 个软件包未被升级。
需要下载 3,145 kB 的归档。
解压缩后会消耗 13.4 MB 的额外空间。
获取:1 http://cn.archive.ubuntu.com/ubuntu xenial/main amd64 sqlite3-doc all 3.11.0-1ubuntu1 [3,145 kB]
已下载 3,145 kB,耗时 8秒 (363 kB/s)
正在选中未选择的软件包 sqlite3-doc。
(正在读取数据库 ... 系统当前共安装有 213313 个文件和目录。)
正准备解包 .../sqlite3-doc_3.11.0-1ubuntu1_all.deb ...
正在解包 sqlite3-doc (3.11.0-1ubuntu1) ...
正在处理用于 doc-base (0.10.7) 的触发器 ...
Processing 1 added doc-base file...
正在设置 sqlite3-doc (3.11.0-1ubuntu1) ...
jiangxin@db01:~$ sqlite3 test.db
SQLite version 3.11.0 2016-02-15 17:29:24
Enter ".help" for usage hints.
sqlite> create table mytable(id integer primary key, value text);
sqlite> insert into mytable(id, value) values(1, 'Micheal');
sqlite> select * from mytable;
1|Micheal
sqlite> .help
.backup ?DB? FILE Backup DB (default "main") to FILE
.bail on|off Stop after hitting an error. Default OFF
.binary on|off Turn binary output on or off. Default OFF
.changes on|off Show number of rows changed by SQL
.clone NEWDB Clone data into NEWDB from the existing database
.databases List names and files of attached databases
.dbinfo ?DB? Show status information about the database
.dump ?TABLE? ... Dump the database in an SQL text format
If TABLE specified, only dump tables matching
LIKE pattern TABLE.
.echo on|off Turn command echo on or off
.eqp on|off Enable or disable automatic EXPLAIN QUERY PLAN
.exit Exit this program
.explain ?on|off|auto? Turn EXPLAIN output mode on or off or to automatic
.fullschema Show schema and the content of sqlite_stat tables
.headers on|off Turn display of headers on or off
.help Show this message
.import FILE TABLE Import data from FILE into TABLE
.indexes ?TABLE? Show names of all indexes
If TABLE specified, only show indexes for tables
matching LIKE pattern TABLE.
.limit ?LIMIT? ?VAL? Display or change the value of an SQLITE_LIMIT
.load FILE ?ENTRY? Load an extension library
.log FILE|off Turn logging on or off. FILE can be stderr/stdout
.mode MODE ?TABLE? Set output mode where MODE is one of:
ascii Columns/rows delimited by 0x1F and 0x1E
csv Comma-separated values
column Left-aligned columns. (See .width)
html HTML <table> code
insert SQL insert statements for TABLE
line One value per line
list Values delimited by .separator strings
tabs Tab-separated values
tcl TCL list elements
.nullvalue STRING Use STRING in place of NULL values
.once FILENAME Output for the next SQL command only to FILENAME
.open ?FILENAME? Close existing database and reopen FILENAME
.output ?FILENAME? Send output to FILENAME or stdout
.print STRING... Print literal STRING
.prompt MAIN CONTINUE Replace the standard prompts
.quit Exit this program
.read FILENAME Execute SQL in FILENAME
.restore ?DB? FILE Restore content of DB (default "main") from FILE
.save FILE Write in-memory database into FILE
.scanstats on|off Turn sqlite3_stmt_scanstatus() metrics on or off
.schema ?TABLE? Show the CREATE statements
If TABLE specified, only show tables matching
LIKE pattern TABLE.
.separator COL ?ROW? Change the column separator and optionally the row
separator for both the output mode and .import
.shell CMD ARGS... Run CMD ARGS... in a system shell
.show Show the current values for various settings
.stats on|off Turn stats on or off
.system CMD ARGS... Run CMD ARGS... in a system shell
.tables ?TABLE? List names of tables
If TABLE specified, only list tables matching
LIKE pattern TABLE.
.timeout MS Try opening locked tables for MS milliseconds
.timer on|off Turn SQL timer on or off
.trace FILE|off Output each SQL statement as it is run
.vfsinfo ?AUX? Information about the top-level VFS
.vfslist List all available VFSes
.vfsname ?AUX? Print the name of the VFS stack
.width NUM1 NUM2 ... Set column widths for "column" mode
Negative values right-justify
sqlite> .quit
jiangxin@db01:~$\
由于Sqlite本身不支持远程访问,如果需要在Windows上连接远程Linux上的Sqlite,需要在Linux上共享文件给Windows。 共享方式见: Ubuntu创建共享文件夹并支持Windows访问:http://jingyan.baidu.com/article/2fb0ba40a8283500f2ec5f35.html
在Windows上打开资源浏览器,在输入框输入\192.168.1.150 然后输入用户名、密码即可
将之前创建的test.db移到share/sqlite目录:
jiangxin@db01:~$ mv test.db share/sqlite/
在Windows上用dbeaver连接Linux上的远程数据库
安装TeraData(SUSE LINUX Enterprise Server 11)
下载、安装VMware-workstation:
VMware-workstation-full-12.5.5-5234757.exe
下载、安装TDExpress
TDExpress14.10.03_Sles11_40GB.7z http://downloads.teradata.com/download/database/teradata-express-for-vmware-player
安装可以参考: http://downloads.teradata.com/database/articles/teradata-express-14-0-for-vmware-user-guide
网络设置
编辑-虚拟网络编辑器
SUSE静态配置IP成功上网: http://blog.csdn.net/seulww/article/details/17136555 按照上面链接设置之后,发现虚拟机无法ping通网关,经查询是DNS配置没有生效。按照下述步骤处理:
修改ip地址(建议通过GUI配置) 即时生效: ifconfig eth0 192.168.1.155 netmask 255.255.255.0 启动生效:修改/etc/sysconfig/network/ifcfg-eth0 修改default gateway(建议通过GUI配置) 即时生效:route add default gw 192.168.1.1 启动生效:修改/etc/sysconfig/network/ifcfg-eth0 修改dns(不知为何通过GUI配置没有生效) 修改/etc/resolv.conf 修改后可即时生效,启动同样有效(一下为修改的内容)
search localdomain nameserver 114.114.114.114 nameserver 8.8.8.8
修改host name(建议通过GUI配置) 即时生效:hostname TDExpress 启动生效:修改/etc/HOSTNAME
启动报错解决
启动之后可以查看/var/log/boot.msg获取此次开机的报错日志。
问题1: Error:cannot mount filesystem:Protocol error Mounting HGFS shares: FAILED
解决:
在VM->Setting中的Option页面,设置Shared Folders,使之enable 就可以了,这个功能能把host上的目录mount到Guest上的/mnt/hgfs目录,实现共享访问。
问题2:
<notice – Apr 16 00:58:00.139375000> ipmi start Starting ipmi drivers: failed <notice – Apr 16 00:58:00.379049000> ‘ipmi start’ exits with status 1
解决: 不影响功能,暂未解决。
使用DBeaver进行连接
安装Oracle
Database Application Development Hands On Labs: http://www.oracle.com/technetwork/database/enterprise-edition/databaseappdev-vm-161299.html
配置网络
[root@vbgeneric ~]# ifconfig
enp0s3: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 1500 inet 192.168.1.105 netmask 255.255.255.0 broadcast 192.168.1.255 ether 08:00:27:0c:40:7f txqueuelen 1000 (Ethernet) RX packets 2677 bytes 2476158 (2.3 MiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 2645 bytes 323609 (316.0 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
lo: flags=73<UP,LOOPBACK,RUNNING> mtu 65536 inet 127.0.0.1 netmask 255.0.0.0 loop txqueuelen 0 (Local Loopback) RX packets 473 bytes 111334 (108.7 KiB) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 473 bytes 111334 (108.7 KiB) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
virbr0: flags=4099<UP,BROADCAST,MULTICAST> mtu 1500 inet 192.168.122.1 netmask 255.255.255.0 broadcast 192.168.122.255 ether 52:54:00:fc:2d:7f txqueuelen 0 (Ethernet) RX packets 0 bytes 0 (0.0 B) RX errors 0 dropped 0 overruns 0 frame 0 TX packets 0 bytes 0 (0.0 B) TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0
[root@vbgeneric ~]# hostname vbgeneric
[root@vbgeneric ~]# vim /etc/sysconfig/network-scripts/ifcfg-enp0s3
TYPE=”Ethernet” BOOTPROTO=”static” NAME=”enp0s3” UUID=”05c05f77-20d5-4842-808d-366b3dc466d4” DEVICE=”enp0s3” ONBOOT=”yes” IPADDR=192.168.1.145 NETMASK=255.255.255.0
[root@vbgeneric ~]# vim /etc/sysconfig/network
NETWORKING=yes HOSTNAME=vbgeneric.localdomain GATEWAY=192.168.1.1
[root@vbgeneric ~]# vim /etc/resolv.conf
nameserver 114.114.114.114 nameserver 8.8.8.8
[root@vbgeneric ~]# service network restart Restarting network (via systemctl): [ OK ]
账号信息
root/oracle
[root@vbgeneric ~]# cat /etc/oracle-release Oracle Linux Server release 7.3 [root@vbgeneric ~]# su - oracle Last login: Sat Sep 2 08:30:31 EDT 2017 on pts/1 [oracle@vbgeneric ~]$ sqlplus / as sysdba
SQL*Plus: Release 12.2.0.1.0 Production on Sat Sep 2 08:39:20 2017
Copyright (c) 1982, 2016, Oracle. All rights reserved.
ERROR: ORA-01017: invalid username/password; logon denied
Enter user-name: sys as sysdba Enter password:
Connected to: Oracle Database 12c Enterprise Edition Release 12.2.0.1.0 - 64bit Production
SQL>
Windows 10 安装 Oracle Database 11.2g
win64_11gR2_database_1of2.zip、win64_11gR2_database_2of2.zip两个解压到同一个目录
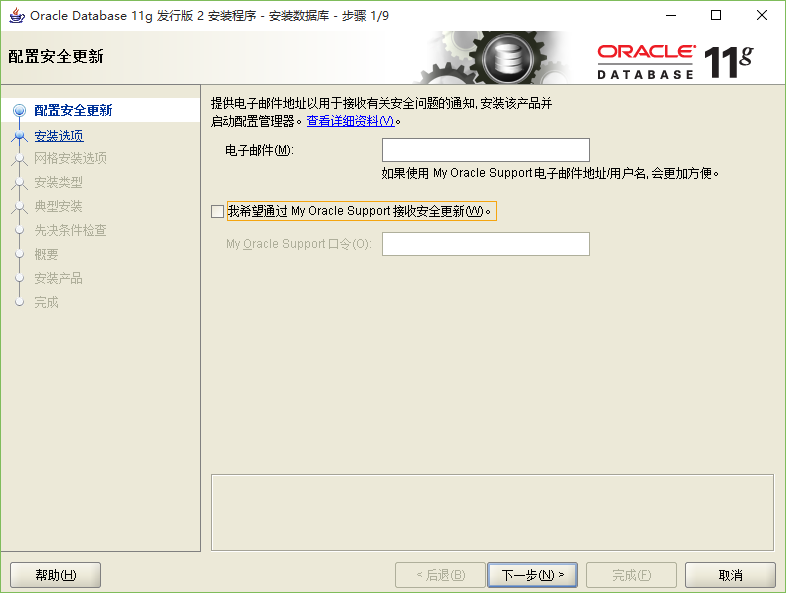

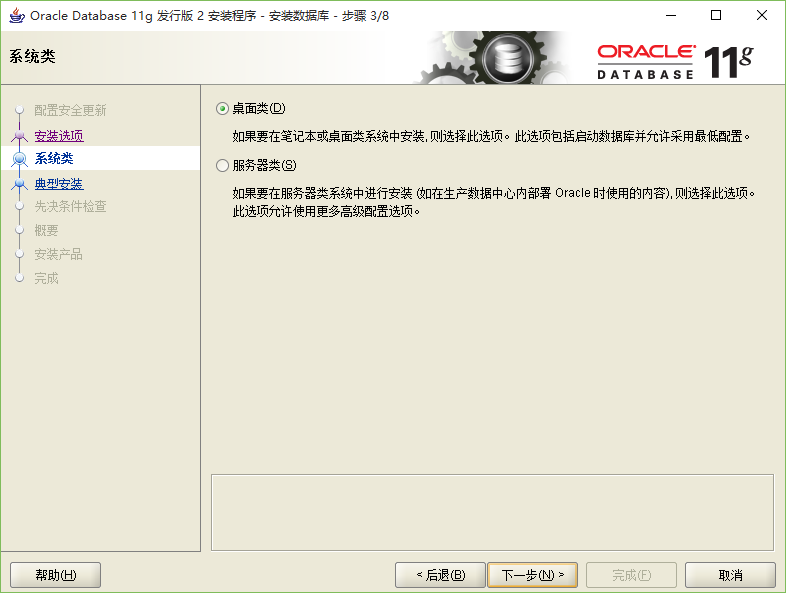
Oracle基目录:$ORACLE_BASE
软件位置:$ORACLE_HOME
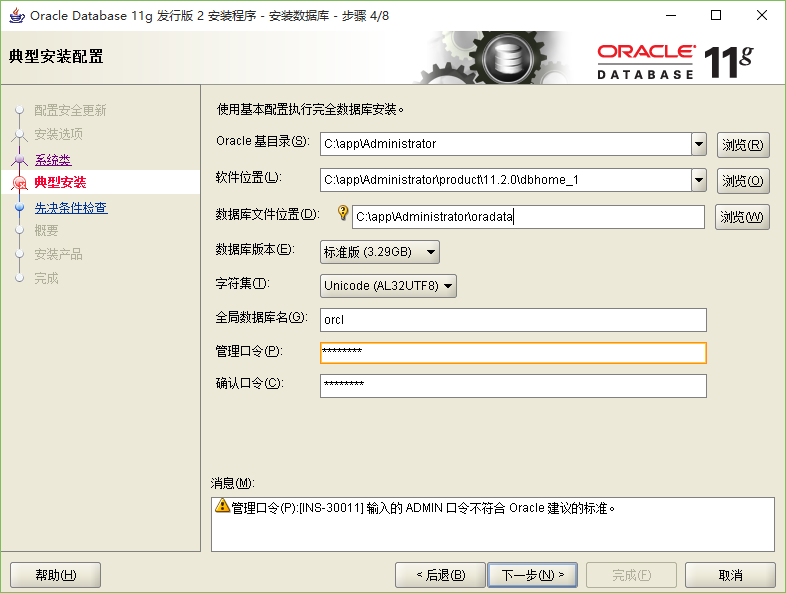

Windows 10 安装 Oracle12c
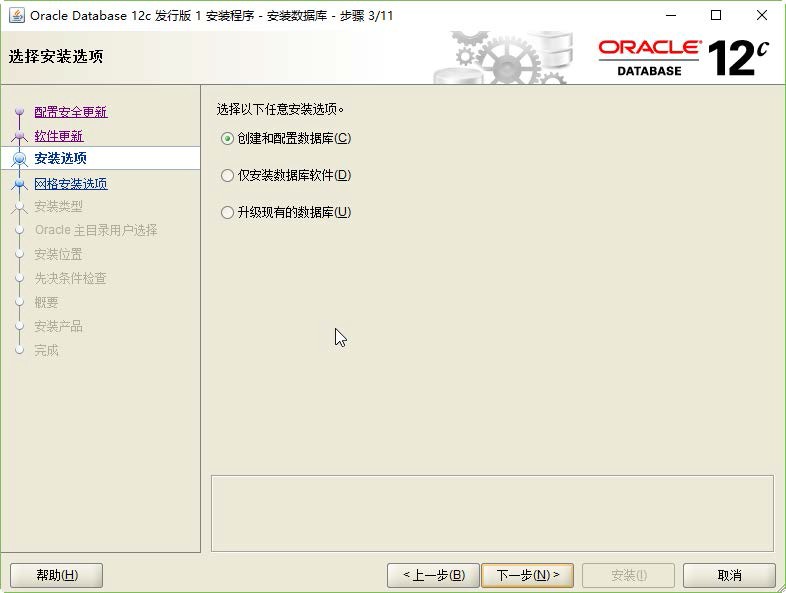
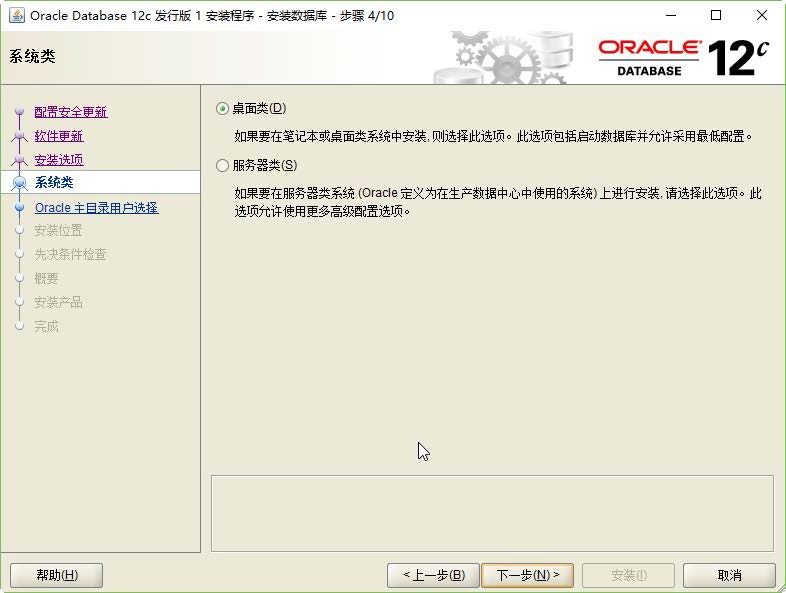
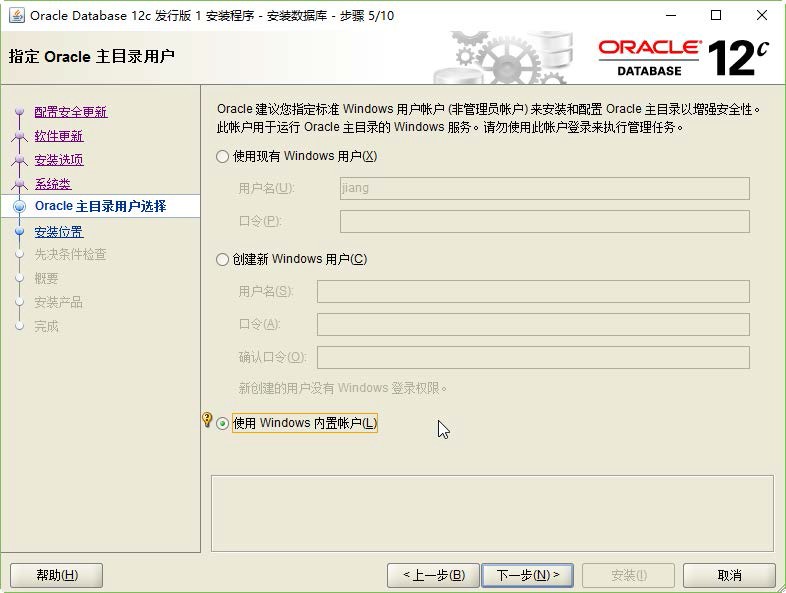
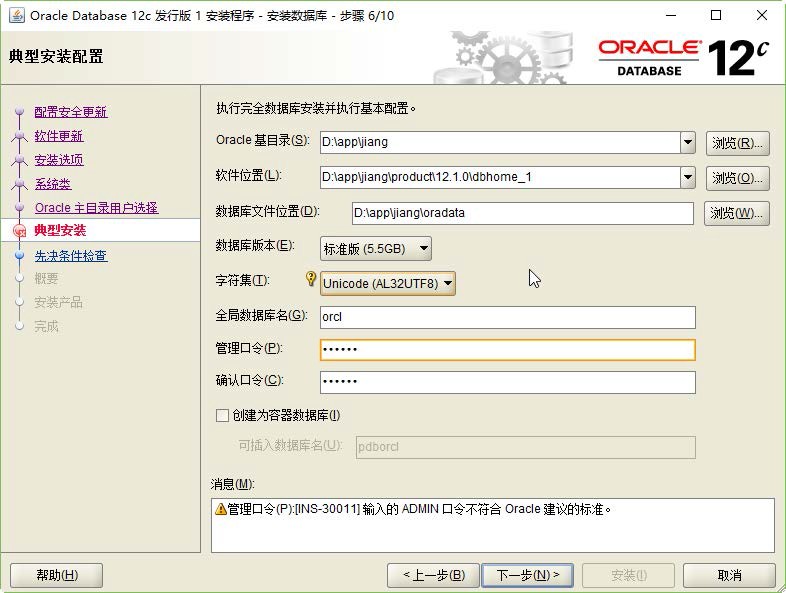
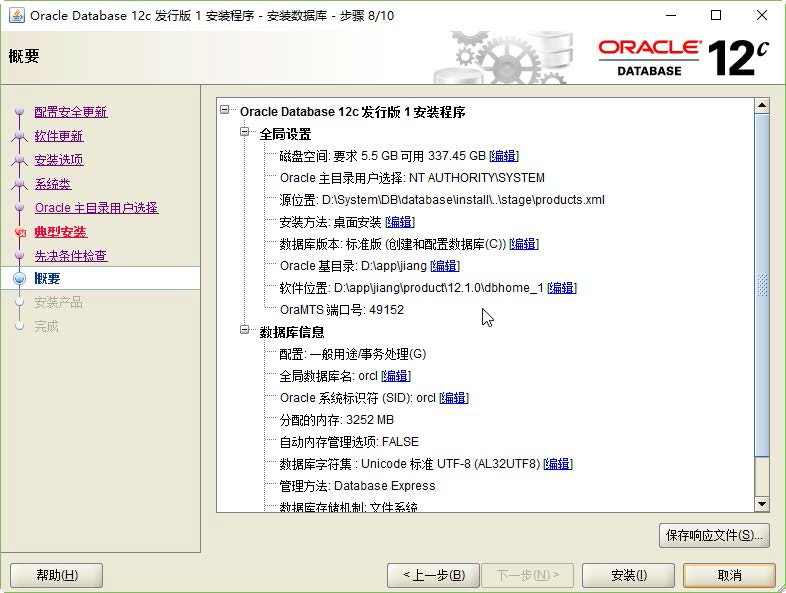

如何利用Oracle VM Templates 在几分钟内部署Oracle Real Application Clusters (RAC)
本文未经授权,禁止一切形式的转载。如果对本文有任何疑问可以通过以下方式和我交流:
邮箱: jiangxinnju@163.com 博客园地址: http://www.cnblogs.com/jiangxinnju GitHub地址: https://github.com/jiangxincode 知乎地址: https://www.zhihu.com/people/jiangxinnju
阅读前准备
阅读本教程前首先需要访问如下地址: http://www.oracle.com/technetwork/server-storage/vm/downloads/hol-oraclevm-2368799.html
 下载红框标识的ovmm10471.oow.local.ova和ovs10471.oow.local.ova文件,并仔细阅读绿框标识的教程(OOW2015_HOL10471_RAC_20151116,以下简称OOW2015_HOL10471_RAC),本文是针对该教程的补充说明。
下载红框标识的ovmm10471.oow.local.ova和ovs10471.oow.local.ova文件,并仔细阅读绿框标识的教程(OOW2015_HOL10471_RAC_20151116,以下简称OOW2015_HOL10471_RAC),本文是针对该教程的补充说明。
另外阅读OOW2015_HOL10471_RAC和本文需要对Oracle VM VirtualBox和Oracle VM有基本的了解,可以访问如下地址: Oracle VM VirtualBox: http://www.oracle.com/technetwork/server-storage/virtualbox/overview/index.html Oracle VM: http://www.oracle.com/technetwork/server-storage/vm/overview/index.html
1 INTRODUCTION
1.1 LAB OBJECTIVE
1.2 PREPARATION (HAS BEEN DONE BEFORE THE LAB)
要想满足和OOW2015_HOL10471_RAC中所述的前提条件,只需要在满足硬件要求的笔记本或者台式机(内存16G以上,CPU 4核以上)中下载安装VirtualBox,进行VirtualBox网络配置,导入之前下载的虚拟机即可。VirtualBox下载地址为: http://www.oracle.com/technetwork/server-storage/virtualbox/downloads/index.html 下载符合宿主机操作系统的VirtualBox并按照提示进行安装。 安装后需要进行基础网络设置,之所以需要基础网络配置是因为如果想在宿主机中访问Oracle VM Manager虚拟机、Oracle VM Server虚拟机以及Oracle VM Server中Oracle RAC虚拟机,需要让宿主机和虚拟机处于一个网段之中,在OOW2015_HOL10471_RAC的1.3章节中可以知道虚拟机的网段是192.168.56.X,所以需要在Virtualbox中添加一个IP地址为192.168.56.1的网卡。添加网卡的步骤如下:
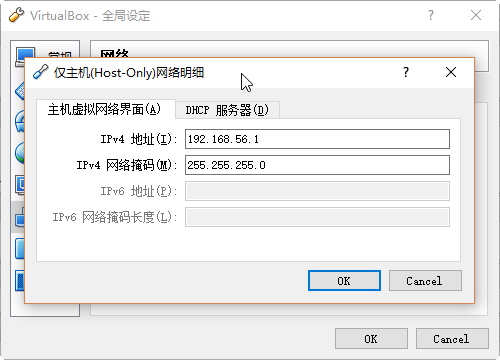
设置之后在【控制面板\网络和 Internet\网络连接】中可以看到配置的网卡

在cmd或者powershell中执行ipconfig命令,可以发现多了一块网卡:
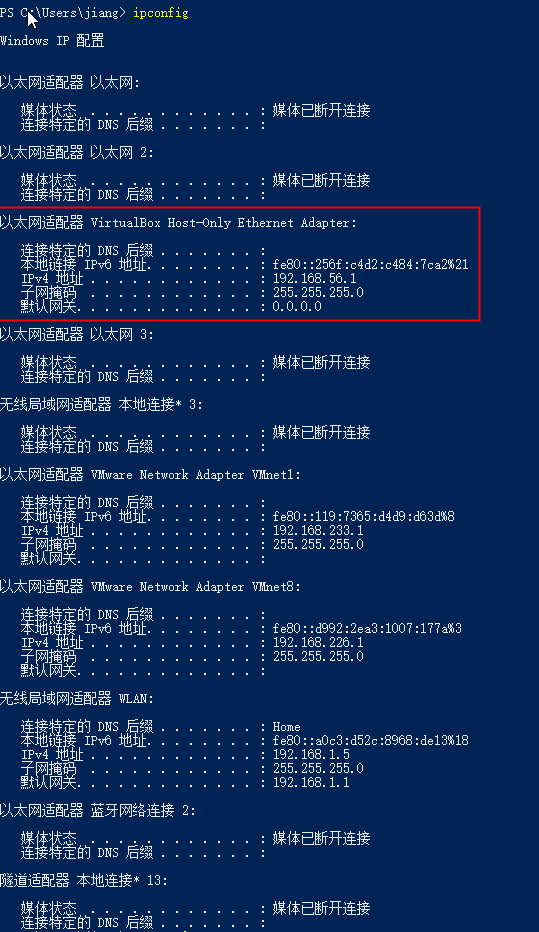
增加网卡之后需要导入Oracle VM Manager+Oracle VM Server模板。首先导入Oracle VM Manager
然后导入Oracle VM Server
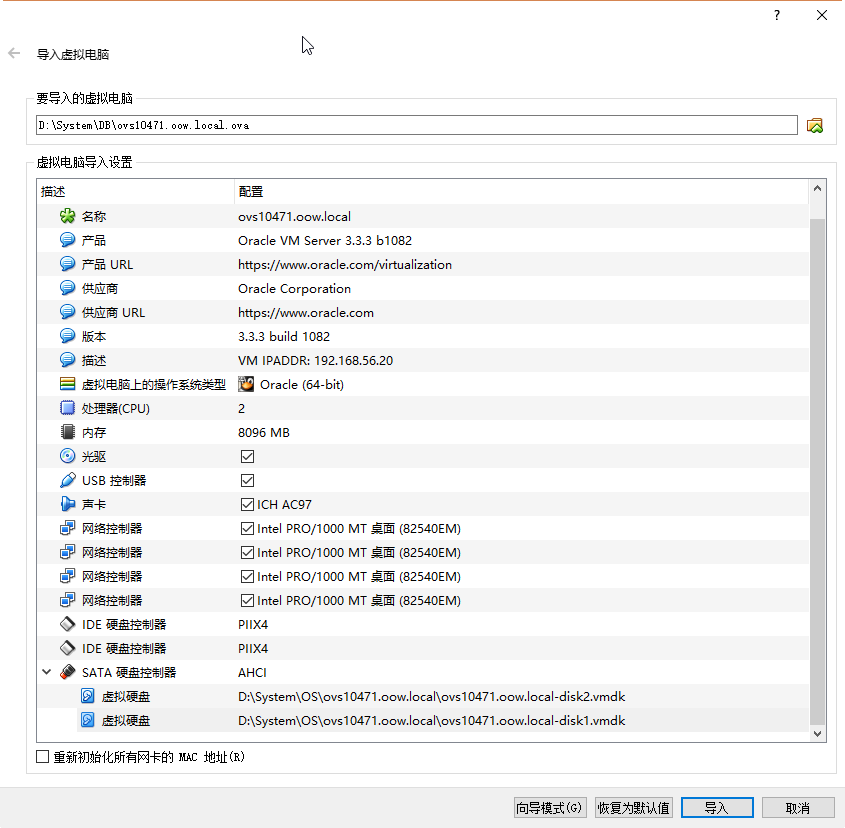
启动虚拟机,如果出现类似于下面的提示:
则重新进行网络设置:
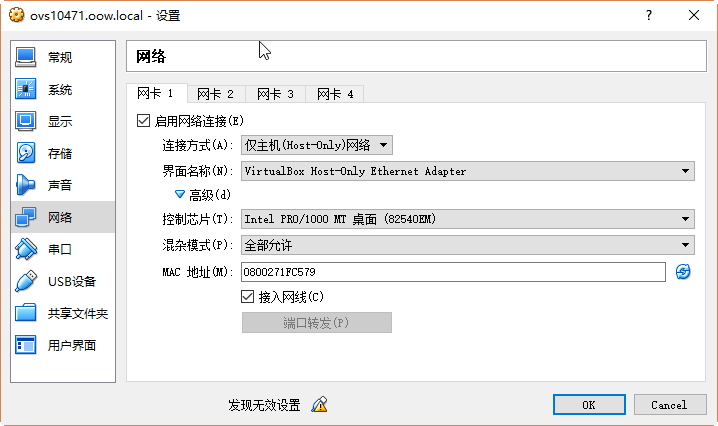
禁用掉OVS的USB控制器
启动虚拟机,直到看到如下界面:

此时在宿主机中ping两台虚拟机的IP地址,应该都是可以ping通的。
1.3 GLOBAL PICTURE
2 DETAILED INSTRUCTIONS
2.1 START BOTH SERVERS (VIRTUAL BOX VMS)
2.2 CONNECT TO THE ORACLE VM MANAGER CONSOLE
如果使用最新的Firefox版本(本文写作时的最新版本是Firefox 56),访问https://192.168.56.30:7002/ovm/console时会提示“建立安全连接失败”:

此时可以使用老版本的Firefox进行访问,47.0版本的Firefox安装包可以从百度网盘进行下载:http://pan.baidu.com/s/1dEBT5df

安装之后首先设置禁止检查更新,防止后台再次更新升级到最新版本。
继续访问https://192.168.56.30:7002/ovm/console 出现如下图提示时单击“添加例外”
点击“确认安全例外”
此时可以看到VM Manager的登陆界面。
2.3 CREATE A STORAGE REPOSITORY
2.4 CLONE 3 VMS FROM DB/RAC ORACLE VM TEMPLATE
2.5 CREATING SHARED DISK FOR ASM CONFIGURATION
在使用ssh连接Oracle VM Manager时如果使用的是Xshell的话,不支持OOW2015_HOL10471_RAC中所提到的ssh命令: ssh admin@192.168.56.30 -p 10000 需要在图形配置页中进行配置,如下:
3 START INSTALLATION USING DEPLOYCLUSTER
3.1 CREATE A NETCONFIG.INI FILE FOR DEPLOYMENT
3.2 RUNNING DEPLOYCLUSTER.PY
在执行deploycluster.py命令时如果出现下图错误说明之前分配给三个虚拟机的资源过少:

此时在浏览器中修改对应的内存值即可:
安装成功的标志是buildcluster.log中出现如下内容:
如何关闭、启动系统
OOW2015_HOL10471_RAC中未提及如何关系和启动系统,这里做简要说明。
关闭系统时首先通过浏览器关闭三台VM:
待节点状态都是Stopped之后关闭Virtualbox 虚拟机
启动系统时反过来,先运行Virtualbox虚拟机:
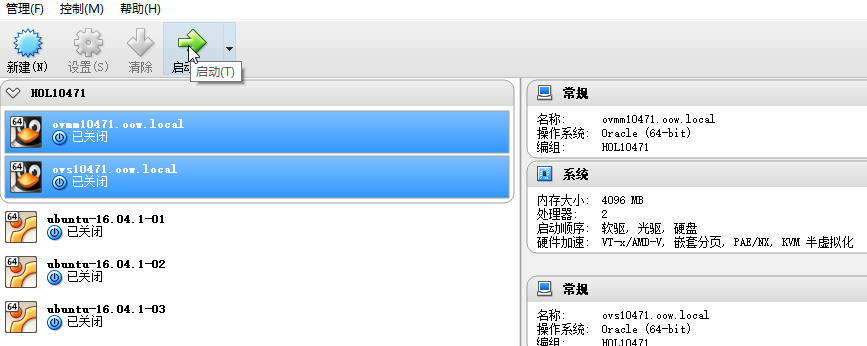
看到如下画面代表Oracle VM Server启动成功:
看到如下画面代表Oracle VM Manager启动成功:
然后使用Firefox浏览器打开OVMM控制台:
待所有节点的状态都为Running时,用SSH登陆到racnode0.1节点,执行crsstat -t。当出现如下结果时说明RAC已经启动成功。
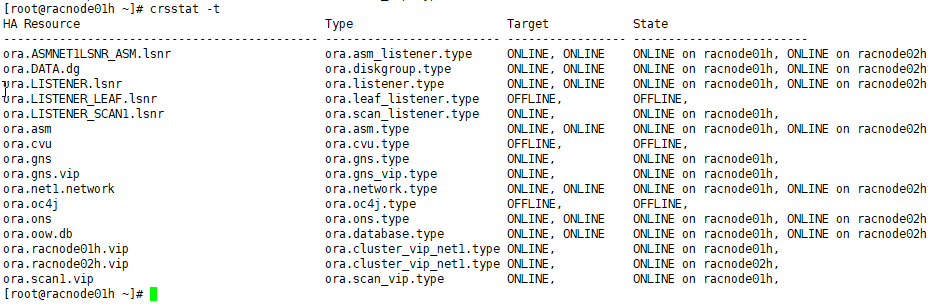
常用Oracle RAC相关的命令
[oracle@racnode01h ~]$ crsctl check css
CRS-4529: Cluster Synchronization Services is online
[oracle@racnode01h ~]$ ps -ef|grep cssd
root 1548 1 0 16:48 ? 00:00:17 /u01/app/12.1.0/grid/bin/cssdmonitor
root 1565 1 0 16:48 ? 00:00:16 /u01/app/12.1.0/grid/bin/cssdagent
oracle 1576 1 1 16:48 ? 00:01:02 /u01/app/12.1.0/grid/bin/ocssd.bin
oracle 4905 2855 0 18:04 pts/0 00:00:00 grep cssd
[oracle@racnode01h ~]$ crsctl check has
CRS-4638: Oracle High Availability Services is online
[oracle@racnode01h ~]$ ps -ef|grep ohasd.bin
root 1195 1 1 16:47 ? 00:01:06 /u01/app/12.1.0/grid/bin/ohasd.bin reboot
oracle 4932 2855 0 18:05 pts/0 00:00:00 grep ohasd.bin
[oracle@racnode01h ~]$ crs_stat -t
Name Type Target State Host
------------------------------------------------------------
ora....SM.lsnr ora....er.type ONLINE ONLINE racnode01h
ora.DATA.dg ora....up.type ONLINE ONLINE racnode01h
ora....ER.lsnr ora....er.type ONLINE ONLINE racnode01h
ora....AF.lsnr ora....er.type OFFLINE OFFLINE
ora....N1.lsnr ora....er.type ONLINE ONLINE racnode01h
ora.asm ora.asm.type ONLINE ONLINE racnode01h
ora.cvu ora.cvu.type OFFLINE OFFLINE
ora.gns ora.gns.type ONLINE ONLINE racnode01h
ora.gns.vip ora....ip.type ONLINE ONLINE racnode01h
ora....network ora....rk.type ONLINE ONLINE racnode01h
ora.oc4j ora.oc4j.type OFFLINE OFFLINE
ora.ons ora.ons.type ONLINE ONLINE racnode01h
ora.oow.db ora....se.type ONLINE ONLINE racnode01h
ora....1H.lsnr application ONLINE ONLINE racnode01h
ora....01h.ons application ONLINE ONLINE racnode01h
ora....01h.vip ora....t1.type ONLINE ONLINE racnode01h
ora....2H.lsnr application ONLINE ONLINE racnode02h
ora....02h.ons application ONLINE ONLINE racnode02h
ora....02h.vip ora....t1.type ONLINE ONLINE racnode02h
ora.scan1.vip ora....ip.type ONLINE ONLINE racnode01h
[oracle@racnode01h ~]$ crsctl status resource -t
--------------------------------------------------------------------------------
Name Target State Server State details
--------------------------------------------------------------------------------
Local Resources
--------------------------------------------------------------------------------
ora.ASMNET1LSNR_ASM.lsnr
ONLINE ONLINE racnode01h STABLE
ONLINE ONLINE racnode02h STABLE
ora.DATA.dg
ONLINE ONLINE racnode01h STABLE
ONLINE ONLINE racnode02h STABLE
ora.LISTENER.lsnr
ONLINE ONLINE racnode01h STABLE
ONLINE ONLINE racnode02h STABLE
ora.LISTENER_LEAF.lsnr
OFFLINE OFFLINE racnode03h STABLE
ora.net1.network
ONLINE ONLINE racnode01h STABLE
ONLINE ONLINE racnode02h STABLE
ora.ons
ONLINE ONLINE racnode01h STABLE
ONLINE ONLINE racnode02h STABLE
--------------------------------------------------------------------------------
Cluster Resources
--------------------------------------------------------------------------------
ora.LISTENER_SCAN1.lsnr
1 ONLINE ONLINE racnode01h STABLE
ora.asm
1 ONLINE ONLINE racnode01h Started,STABLE
2 ONLINE ONLINE racnode02h Started,STABLE
3 OFFLINE OFFLINE STABLE
ora.cvu
1 OFFLINE OFFLINE STABLE
ora.gns
1 ONLINE ONLINE racnode01h STABLE
ora.gns.vip
1 ONLINE ONLINE racnode01h STABLE
ora.oc4j
1 OFFLINE OFFLINE STABLE
ora.oow.db
1 ONLINE ONLINE racnode01h Open,STABLE
2 ONLINE ONLINE racnode02h Open,STABLE
ora.racnode01h.vip
1 ONLINE ONLINE racnode01h STABLE
ora.racnode02h.vip
1 ONLINE ONLINE racnode02h STABLE
ora.scan1.vip
1 ONLINE ONLINE racnode01h STABLE
--------------------------------------------------------------------------------
[oracle@racnode01h ~]$ sqlplus / as sysdba
SQL*Plus: Release 12.1.0.2.0 Production on Fri Nov 10 18:14:09 2017
Copyright (c) 1982, 2014, Oracle. All rights reserved.
Connected to:
Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 - 64bit Production
With the Partitioning, Real Application Clusters, Automatic Storage Management, OLAP,
Advanced Analytics and Real Application Testing options
SQL> set linesize 200;
SQL> select * from gv$instance;
INST_ID INSTANCE_NUMBER INSTANCE_NAME HOST_NAME VERSION STARTUP_T STATUS PAR THREAD# ARCHIVE LOG_SWITCH_WAIT LOGINS
---------- --------------- ---------------- ---------------------------------------------------------------- ----------------- --------- ------------ --- ---------- ------- --------------- ----------
SHU DATABASE_STATUS INSTANCE_ROLE ACTIVE_ST BLO CON_ID INSTANCE_MO EDITION FAMILY
--- ----------------- ------------------ --------- --- ---------- ----------- ------- --------------------------------------------------------------------------------
1 1 OOW1 racnode01h 12.1.0.2.0 10-NOV-17 OPEN YES 1 STOPPED ALLOWED
NO ACTIVE PRIMARY_INSTANCE NORMAL NO 0 REGULAR EE
2 2 OOW2 racnode02h 12.1.0.2.0 10-NOV-17 OPEN YES 2 STOPPED ALLOWED
NO ACTIVE PRIMARY_INSTANCE NORMAL NO 0 REGULAR EE
SQL>
安装PLSQL Developer 11.0.6
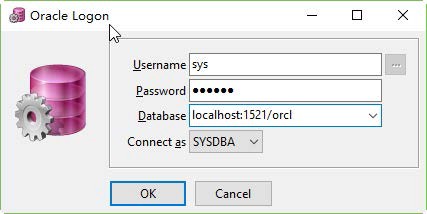
安装Prometheus
下载地址: https://prometheus.io/download/
jiangxin@tomcat:~$ sudo mkdir /usr/local/prometheus jiangxin@tomcat:~$ sudo chown -R jiangxin:jiangxin /usr/local/prometheus jiangxin@tomcat:~$ cd /usr/local/prometheus/ jiangxin@tomcat:/usr/local/prometheus$ ls prometheus-1.7.1.linux-amd64.tar.gz jiangxin@tomcat:/usr/local/prometheus$ tar -zxvf prometheus-1.7.1.linux-amd64.tar.gz jiangxin@tomcat:/usr/local/prometheus$ cd prometheus-1.7.1.linux-amd64/
jiangxin@tomcat:/usr/local/prometheus/prometheus-1.7.1.linux-amd64$ sudo vim /etc/profile
export PROMETHEUS_HOME=/usr/local/prometheus/prometheus-1.7.1.linux-amd64 export PATH=$PATH:$PROMETHEUS_HOME
jiangxin@tomcat:/usr/local/prometheus/prometheus-1.7.1.linux-amd64$ source /etc/profile jiangxin@tomcat:/usr/local/prometheus/prometheus-1.7.1.linux-amd64$ cd
启动
jiangxin@tomcat:~$ prometheus -config.file=${PROMETHEUS_HOME}/prometheus.yml INFO[0000] Starting prometheus (version=1.7.1, branch=master, revision=3afb3fffa3a29c3de865e1172fb740442e9d0133) source=”main.go:88” INFO[0000] Build context (go=go1.8.3, user=root@0aa1b7fc430d, date=20170612-11:44:05) source=”main.go:89” INFO[0000] Host details (Linux 4.4.0-78-generic #99-Ubuntu SMP Thu Apr 27 15:29:09 UTC 2017 x86_64 tomcat (none)) source=”main.go:90” INFO[0000] Loading configuration file /usr/local/prometheus/prometheus-1.7.1.linux-amd64/prometheus.yml source=”main.go:252” INFO[0000] Loading series map and head chunks… source=”storage.go:428” INFO[0000] 0 series loaded. source=”storage.go:439” INFO[0000] Starting target manager… source=”targetmanager.go:63” INFO[0000] Listening on :9090 source=”web.go:259”
查看界面
http://192.168.1.130:9090/metrics
http://192.168.1.130:9090/graph
安装配置CAS
基础环境安装
搭建CAS单点登录系统,首先需要基础环境的部署。主要包括Windows/Linux/Java/Maven/GIT/Tomcat等,基础环境的部署不是本文的描写重点,本文仅做简要说明,如有疑问可以邮件咨询。
Windows
Windows 10,安装有JDK/GIT/Maven等工具,主要功能是下载CAS服务端和客户端源码,并进行编译打包,上传到Linux服务器上进行部署。同时利用Chrome浏览器对安装之后的环境进行检验。
Linux
Ubuntu 16.04.1 LTS,安装有JDK、Tomcat等工具,主要作为CAS Server和Web Server的宿主环境。
JDK
Linux服务器端安装JDK主要是作为Tomcat的运行时环境,并提供keytool等工具进行HTTPS配置;Windows客户端安装JDK主要是作为Maven的运行时环境。
jiangxin@tomcat:~$ java -version java version “1.8.0_121” Java(TM) SE Runtime Environment (build 1.8.0_121-b13) Java HotSpot(TM) 64-Bit Server VM (build 25.121-b13, mixed mode)
PS C:\Users\jiang> java -version java version “1.8.0_102” Java(TM) SE Runtime Environment (build 1.8.0_102-b14) Java HotSpot(TM) 64-Bit Server VM (build 25.102-b14, mixed mode)
GIT
安装在Windows机器,主要用于下载并及时更新CAS Server和Client源码。 PS C:\Users\jiang> git –version git version 2.8.3.windows.1
Maven
安装在Windows机器,主要作用是编译打包。 PS C:\Users\jiang> mvn -v Apache Maven 3.3.9 (bb52d8502b132ec0a5a3f4c09453c07478323dc5; 2015-11-11T00:41:47+08:00) Maven home: C:\apache-maven-3.3.9 Java version: 1.8.0_102, vendor: Oracle Corporation Java home: C:\Java\jdk1.8.0_102\jre Default locale: zh_CN, platform encoding: GBK OS name: “windows 10”, version: “10.0”, arch: “amd64”, family: “dos”
Tomcat
安装在Linux,安装包为: apache-tomcat-8.5.14.tar.gz 为了更好的模拟单点登录,需要安装三个Tomcat实例,其中一个作为CAS Server,另外两个作为CAS Client。具体分配
安装过程为: jiangxin@tomcat:/usr/local$ sudo mkdir tomcat jiangxin@tomcat:/usr/local$ sudo chown -R jiangxin:jiangxin tomcat/ jiangxin@tomcat:/usr/local$ cd tomcat/ jiangxin@tomcat:/usr/local/tomcat$ ls jiangxin@tomcat:/usr/local/tomcat$ tar -zxvf apache-tomcat-8.5.14.tar.gz jiangxin@tomcat:/usr/local/tomcat$ cd
jiangxin@tomcat:~$ sudo vim /etc/profile
export CATALINA_BASE=/usr/local/tomcat/apache-tomcat-8.5.14 export CATALINA_HOME=/usr/local/tomcat/apache-tomcat-8.5.14 export PATH=$PATH:$CATALINA_HOME/lib:$CATALINA_HOME/bin
jiangxin@tomcat:~$ source /etc/profile
jiangxin@tomcat:~$ startup.sh ; tailf $CATALINA_HOME/logs/catalina.out Using CATALINA_BASE: /usr/local/tomcat/apache-tomcat-8.5.14 Using CATALINA_HOME: /usr/local/tomcat/apache-tomcat-8.5.14 Using CATALINA_TMPDIR: /usr/local/tomcat/apache-tomcat-8.5.14/temp Using JRE_HOME: /usr/local/java/jdk1.8.0_121 #限于篇幅,此处有省略 05-May-2017 20:27:53.487 信息 [main] org.apache.catalina.startup.Catalina.start Server startup in 1633 ms
在浏览器中访问下面地址,查看能否正常访问:
http://192.168.1.130:8080/
jiangxin@tomcat:~$ shutdown.sh Using CATALINA_BASE: /usr/local/tomcat/apache-tomcat-8.5.14 Using CATALINA_HOME: /usr/local/tomcat/apache-tomcat-8.5.14 Using CATALINA_TMPDIR: /usr/local/tomcat/apache-tomcat-8.5.14/temp Using JRE_HOME: /usr/local/java/jdk1.8.0_121 Using CLASSPATH: /usr/local/tomcat/apache-tomcat-8.5.14/bin/bootstrap.jar:/usr/local/tomcat/apache-tomcat-8.5.14/bin/tomcat-juli.jar
安装CAS服务端
在较新的CAS版本中不在提供CAS服务端和客户端的安装包,都是依靠下载源码,重新打包。如果对本文的安装内容有疑问可以参考CAS的官网:
https://apereo.github.io/cas/5.0.x/installation/Maven-Overlay-Installation.html https://github.com/apereo/cas-overlay-template
正常情况下应该在服务器上进行maven编译,这样才能保证编译的JDK版本和运行时的版本一致,但是此处为了方便,直接在Windows编译。
PS C:\Users\jiang> cd D:\temp\Java
PS D:\temp\Java> git clone https://github.com/apereo/cas-overlay-template.git
Cloning into ‘cas-overlay-template’…
remote: Counting objects: 566, done.
remote: Compressing objects: 100% (12/12), done.
remote: Total 566 (delta 4), reused 0 (delta 0), pack-reused 550 eceiving objects: 96% (544/566), 116.00 KiB | 79.00 KiB/
Receiving objects: 100% (566/566), 188.70 KiB | 79.00 KiB/s, done.
Resolving deltas: 100% (275/275), done.
Checking connectivity… done.
PS D:\temp\Java> cd .\cas-overlay-template
PS D:\temp\Java\cas-overlay-template> .\build.cmd package
[INFO] Scanning for projects…
[INFO]
[INFO] Using the MultiThreadedBuilder implementation with a thread count of 5
[INFO]
[INFO] ————————————————————————
[INFO] Building cas-overlay 1.0
由于篇幅原因,此处有省略
[INFO] Packaging webapp
[INFO] Assembling webapp [cas-overlay] in [D:\temp\Java\cas-overlay-template\target\cas]
[info] Copying manifest…
[INFO] Processing war project
[INFO] Processing overlay [ id org.apereo.cas:cas-server-webapp]
[INFO] Webapp assembled in [2685 msecs]
[INFO] Building war: D:\temp\Java\cas-overlay-template\target\cas.war
[INFO] ————————————————————————
[INFO] BUILD SUCCESS
[INFO] ————————————————————————
[INFO] Total time: 06:34 min (Wall Clock)
[INFO] Finished at: 2017-05-05T20:06:02+08:00
[INFO] Final Memory: 13M/200M
[INFO] ————————————————————————
把cas-overlay-template\target\cas.war上传到/usr/local/tomcat/apache-tomcat-8.5.14/webapps
重新启动tomcat
05-May-2017 20:39:10.561 信息 [main] org.apache.catalina.startup.VersionLoggerListener.log Server version: Apache Tomcat/8.5.14 由于篇幅原因,此处有省略 05-May-2017 20:39:11.026 信息 [localhost-startStop-1] org.apache.catalina.startup.HostConfig.deployWAR Deploying web application archive /usr/local/tomcat/apache-tomcat-8.5.14/webapps/cas.war 05-May-2017 20:39:20.915 信息 [localhost-startStop-1] org.apache.jasper.servlet.TldScanner.scanJars At least one JAR was scanned for TLDs yet contained no TLDs. Enable debug logging for this logger for a complete list of JARs that were scanned but no TLDs were found in them. Skipping unneeded JARs during scanning can improve startup time and JSP compilation time.
/ / / | / \ / __| \ \ | | | | / _ \ _ \ | | | | | |_ / ___ \ __) | | | | | _|// _|__/ | | _\ //
CAS Version: 5.0.5 Apache Tomcat Version: Apache Tomcat/8.5.14 Build Date/Time: 2017-04-21T03:24:20Z System Temp Directory: /usr/local/tomcat/apache-tomcat-8.5.14/temp Java Home: /usr/local/java/jdk1.8.0_121/jre Java Vendor: Oracle Corporation Java Version: 1.8.0_121 JCE Installed: no OS Architecture: amd64 OS Name: Linux OS Version: 4.4.0-72-generic
2017-05-05 20:39:29,134 INFO [org.apereo.cas.web.CasWebApplicationServletInitializer] - <The following profiles are active: native>
在浏览器中范围如下地址,查看能否访问: http://192.168.1.130:8080/cas/login
使用casuser/Mellon进行登录(application.properties中配置用户名和密码),查看是否登录成功。

配置数字证书
CAS要求CAS Server和CAS Client以及客户端浏览器端全部使用https访问,所以需要配置证书。
正常情况下,数字证书的生成,分发,使用是在多台机器上,以本文搭建的SSO系统为例,在A机器(CA)上生成证书,然后将证书(包括私钥和公钥)分发到B机器(SSO Server),B机器根据该证书导出公钥分发给C机器(SSO Client),此时B和C即可正常建立连接。同时当D机器(客户端浏览器)与A机器交互时即可在A机器上下载公钥,进行连接。 但为了方便测试,本文中A、B、C机器为一台。
下边的命令,会创建一条证书记录并写入cacerts。证书记录信息包含该条证书的私钥,公钥和对应的数字证书的信息。
jiangxin@tomcat:~$ keytool -genkey -alias castest -keyalg RSA -keystore /usr/local/java/jdk1.8.0_121/jre/lib/security/cacerts
输入密钥库口令: # 按照JDK后,默认的密钥库密码为changeit
您的名字与姓氏是什么? # 名字与姓氏为CAS跳转域名
[Unknown]: cas.sso.com
您的组织单位名称是什么?
[Unknown]: castest
您的组织名称是什么?
[Unknown]: castest
您所在的城市或区域名称是什么?
[Unknown]: nanjing
您所在的省/市/自治区名称是什么?
[Unknown]: jiangsu
该单位的双字母国家/地区代码是什么?
[Unknown]: cn
CN=cas.sso.com, OU=castest, O=castest, L=nanjing, ST=jiangsu, C=cn是否正确?
[否]: y
输入 <castest> 的密钥口令
(如果和密钥库口令相同, 按回车):
可使用如下命令查看证书信息:
jiangxin@tomcat:~$ keytool -list -keystore “$JAVA_HOME/jre/lib/security/cacerts” -alias castest
输入密钥库口令:
castest, 2017-5-7, PrivateKeyEntry,
证书指纹 (SHA1): 9A:9A:DF:AB:18:B7:D9:81:8D:24:BA:E3:73:99:67:CE:58:B0:3A:CD
如果要更新证书,可以先删除原证书,再导入新证书: jiangxin@tomcat:~$ keytool -delete -alias castest -keystore /usr/local/java/jdk1.8.0_121/jre/lib/security/cacerts
接下来修改server.xml文件 jiangxin@tomcat:~$ cp /usr/local/tomcat/apache-tomcat-8.5.14/conf/server.xml /usr/local/tomcat/apache-tomcat-8.5.14/conf/server.xml.bak jiangxin@tomcat:~$ vim /usr/local/tomcat/apache-tomcat-8.5.14/conf/server.xml
<Connector port="8443" protocol="org.apache.coyote.http11.Http11NioProtocol"
maxThreads="150" SSLEnabled="true" scheme="https" secure="true" maxHttpHeaderSize="8192"
clientAuth="false" sslProtocol="TLS"
keystoreFile="/usr/local/java/jdk1.8.0_121/jre/lib/security/cacerts"
keystorePass="changeit">
</Connector>
重启tomcat,访问下面地址,查看是否能够正常访问: https://192.168.1.130:8443/cas
由于本文所部署的环境是CAS Server和CAS Client在一台服务器上,所以不需要单独将公钥导出到CAS Client上,但是如果需要,可以参考下面的导入导出过程。
导出数字证书,数字证书包含三部分信息:证书元数据信息,序列号,过期时间等、所有者信息,姓名、地区等、所有者公钥;相比于在keystore中的信息,没有所有者的密钥,所有者的密钥只有所有者自己知道,而此处的数字证书是要分发到公网上的。
jiangxin@tomcat:~$ keytool -export -file ssokey/castest.crt -alias castest -keystore ssokey/castest
输入密钥库口令:
存储在文件 <ssokey/castest.crt> 中的证书
jiangxin@tomcat:~$ keytool -import -keystore “$JAVA_HOME/jre/lib/security/cacerts” -file ssokey/castest.crt -alias castest
输入密钥库口令:
keytool 错误: java.io.IOException: Keystore was tampered with, or password was incorrect
jiangxin@tomcat:~$ keytool -import -keystore “$JAVA_HOME/jre/lib/security/cacerts” -file ssokey/castest.crt -alias castest
输入密钥库口令:
所有者: CN=cas.sso.com, OU=castest, O=castest, L=nanjing, ST=jiangsu, C=cn
发布者: CN=cas.sso.com, OU=castest, O=castest, L=nanjing, ST=jiangsu, C=cn
序列号: 3cc98964
有效期开始日期: Sun May 07 09:03:47 CST 2017, 截止日期: Sat Aug 05 09:03:47 CST 2017
证书指纹:
MD5: F4:B8:E4:B1:07:EE:86:45:C7:96:5F:FA:EF:E9:5C:11
SHA1: D0:7B:BB:30:0C:D3:8A:49:C9:89:3B:E0:C4:C0:98:30:74:E3:15:98
SHA256: 4B:AB:EA:C1:06:3F:0D:3B:A2:C9:3C:F7:45:B6:CF:66:EA:BE:B3:6A:42:61:05:E3:C4:D4:AE:DC:0C:DC:20:31
签名算法名称: SHA256withRSA
版本: 3
扩展:
#1: ObjectId: 2.5.29.14 Criticality=false SubjectKeyIdentifier [ KeyIdentifier [ 0000: D0 C7 06 22 8B 57 71 E4 39 08 E5 05 F9 5B B4 2D …“.Wq.9….[.- 0010: ED 9F 92 28 …( ] ]
是否信任此证书? [否]: y 证书已添加到密钥库中
安装CAS客户端
建立客户端工程,参考:
https://bitbucket.org/jiangxincode/casclient/
使用maven打包,得到casclient.war,上传到服务器上
验证
验证之前先在Windows和Linux机器的hosts文件中加入: 192.168.1.130 cas.sso.com
重新启动Tomcat容器,在浏览器访问如下地址: https://cas.sso.com:8443/casclient/index.jsp 会发现浏览器被重定向到如下地址: https://cas.sso.com:8443/cas/login?service=https%3A%2F%2Fcas.sso.com%3A8443%2Fcasclient%2Findex.jsp 输入casuser/Mellon之后,浏览器会跳转到下面的地址 https://cas.sso.com:8443/casclient/index.jsp;jsessionid=23551AEBF9B7B61431D0CC942F923771
配置日志路径
为了防止在不同地方启动tomcat,导致日志位置不同,不方便查找,修改一下日志路径。
jiangxin@tomcat:/usr/local/tomcat/apache-tomcat-8.5.14/webapps/cas/WEB-INF/classes$ cp log4j2.xml log4j2.xml.bak jiangxin@tomcat:/usr/local/tomcat/apache-tomcat-8.5.14/webapps/cas/WEB-INF/classes$ vim log4j2.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!-- Specify the refresh internal in seconds. -->
<Configuration monitorInterval="10">
<Properties>
<Property name="CAS_LOG_DIR">/usr/local/tomcat/apache-tomcat-8.5.14/logs/cas</Property>
</Properties>
<Appenders>
<Console name="console" target="SYSTEM_OUT">
<PatternLayout pattern="%d %p [%c] - <%m>%n"/>
</Console>
<RollingFile name="file" fileName="${CAS_LOG_DIR}/cas.log" append="true"
filePattern="cas-%d{yyyy-MM-dd-HH}-%i.log">
<PatternLayout pattern="%d %p [%c] - <%m>%n"/>
<Policies>
<OnStartupTriggeringPolicy />
<SizeBasedTriggeringPolicy size="10 MB"/>
<TimeBasedTriggeringPolicy />
</Policies>
</RollingFile>
<RollingFile name="auditlogfile" fileName="${CAS_LOG_DIR}/cas_audit.log" append="true"
filePattern="cas_audit-%d{yyyy-MM-dd-HH}-%i.log">
<PatternLayout pattern="%d %p [%c] - %m%n"/>
<Policies>
<OnStartupTriggeringPolicy />
<SizeBasedTriggeringPolicy size="10 MB"/>
<TimeBasedTriggeringPolicy />
</Policies>
</RollingFile>
<RollingFile name="perfFileAppender" fileName="${CAS_LOG_DIR}/perfStats.log" append="true"
filePattern="perfStats-%d{yyyy-MM-dd-HH}-%i.log">
<PatternLayout pattern="%m%n"/>
<Policies>
<OnStartupTriggeringPolicy />
<SizeBasedTriggeringPolicy size="10 MB"/>
<TimeBasedTriggeringPolicy />
</Policies>
</RollingFile>
<CasAppender name="casAudit">
<AppenderRef ref="auditlogfile" />
</CasAppender>
<CasAppender name="casFile">
<AppenderRef ref="file" />
</CasAppender>
<CasAppender name="casConsole">
<AppenderRef ref="console" />
</CasAppender>
<CasAppender name="casPerf">
<AppenderRef ref="perfFileAppender" />
</CasAppender>
</Appenders>
#限于篇幅,此处有省略
</Configuration>
其它配置
CAS支持的配置很多,此处不一一说明,有需要的可以参考下面的链接:
https://github.com/apereo/cas CAS protocol: https://apereo.github.io/cas/5.0.x/protocol/CAS-Protocol.html CAS Client集群环境的问题及解决方案: https://yq.aliyun.com/articles/49871 cas系列文章: http://www.cnblogs.com/vhua/tag/cas/ cas单点登录配置速成: http://www.blogjava.net/goodlyts/archive/2009/10/20/299091.html
Windows 10系统下搭建Jenkins环境
主要参考: http://www.cnblogs.com/edward2013/p/5269465.html 但是没有安装ant,而且java、maven、tomcat都是使用的压缩包方式安装。
Ubuntu 16.04安装docker
主要参考: https://docs.docker.com/engine/install/ubuntu/#install-using-the-repository
Ubuntu 22.04安装Samba
下载/安装Samba服务器:
sudo apt-get install samba samba-common
配置Samba服务器
首先将默认的配置文件进行备份 sudo cp /etc/samba/smb.conf /etc/samba/smb.conf.bak
sudo vim /etc/samba/smb.conf
[jiangxin] path = /home/jiangxin available = yes browseable = yes public = yes writable = yes valid users = jiangxin
设置密码并重启服务器
sudo smbpasswd -a jiangxin //设置访问的密码 sudo service smbd restart //重启smb服务器
访问
在Windows资源管理器导航栏输入\\ip_adress,然后输入账号和密码就可以访问了。为了后续方便快速访问Linux侧目录,将远程目录映射为网络驱动器:
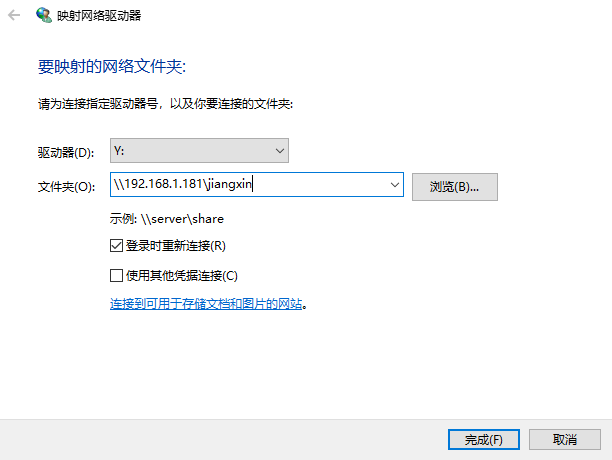
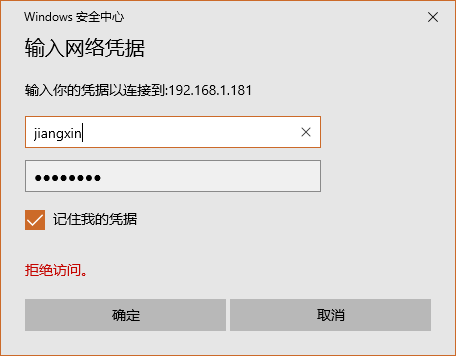
其它问题
如果Windows无法访问samba服务器,尝试通过以下方式确认问题所在:
控制面板-系统和安全-Windows Defender 防火墙,关闭防火墙
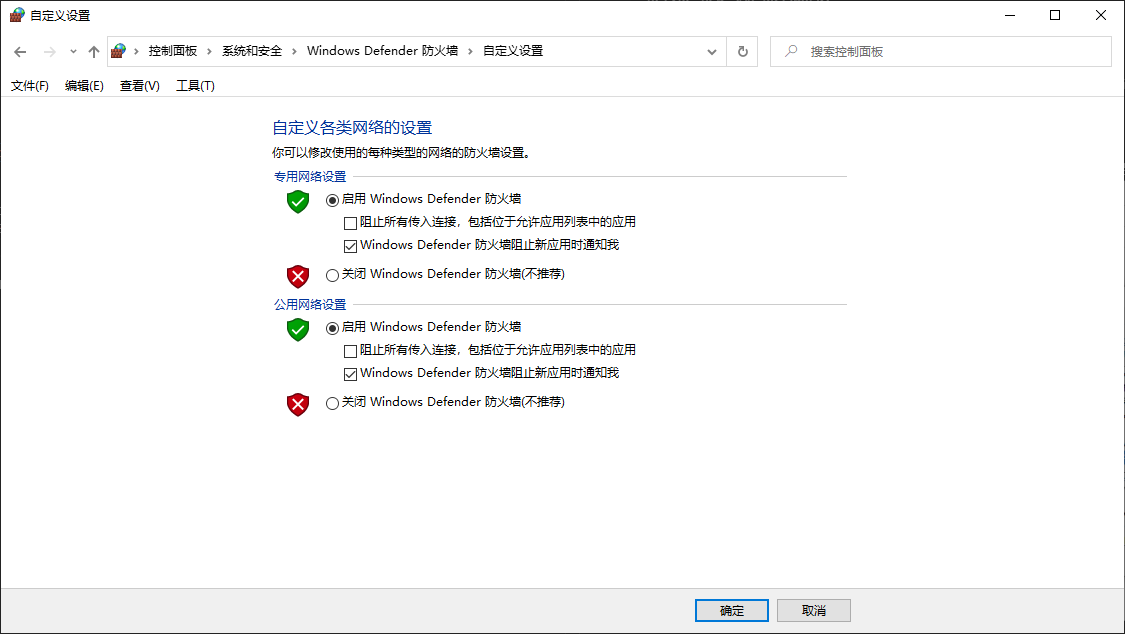 控制面板-程序-启用或关闭Windows功能,勾选SMB 1.0/CIFS文件共享支持
控制面板-程序-启用或关闭Windows功能,勾选SMB 1.0/CIFS文件共享支持
 Win+R,输入gpedit.msc,计算器配置-管理模板-网络-Lanman工作站,选中”不安全的来宾登陆”,在新的对话框中选中”已启用”
Win+R,输入gpedit.msc,计算器配置-管理模板-网络-Lanman工作站,选中”不安全的来宾登陆”,在新的对话框中选中”已启用”
配置AOSP源码查看环境
在Windows上安装Repo,同步AOSP代码【不推荐】
第一个想到的方案是在Windows上配置Repo,然后下载AOSP源码,参考: Windows安装repo的真正解决方案:https://ysy950803.blog.csdn.net/article/details/104188793 但是就像Repo官网(https://gerrit.googlesource.com/git-repo/+/HEAD/docs/windows.md)说的那样: Repo is primarily developed on Linux with a lot of users on macOS. Windows is, unfortunately, not a common platform. There is support in repo for Windows, but there might be some rough edges. Keep in mind that Windows in general is “best effort” and “community supported”. That means we don’t actively test or verify behavior, but rely heavily on users to report problems back to us, and to contribute fixes as needed. Windows版的Repo虽然可用,但是可能会出现各种各样的问题,这些问题可能会让我们在解决环境问题上分心过多,所以不推荐这种方式。
在Linux上安装Repo,同步AOSP代码【推荐】
根据实际情况有两种工作模式: 1、 Linux作为AOSP代码的同步、存储、查看、修改、编译环境,大部分工作都是在Linux上完成,Android Studio也是安装在Linux上,这种我觉得是最完美的模式。但是要求Linux的性能足够好。由于我这边没有实际的Linux机器,是在Windows上用虚拟机配置的Linux环境,所以没有采用这种方法。 2、 Linux作为AOSP代码的同步、存储、编译环境,查看和修改工作在Windows上完成,具体的实现方式有两种: a) 用Samba服务器把Linux上的AOSP代码共享到Windows平台,然后在Windows平台上安装IDE环境,直接打开远程AOSP代码目录,查看和修改,这种方式的优点是配置简单,不用代码同步。但是我这边网速一般,而AOSP代码量太大,导致Android Studio经常卡死,所以我也放弃了这种方式。 b) 将android.iml/android.ipr以及常用的仓(比如frameworks/base frameworks/native等)使用rsync等工具同步到Windows平台,然后在Windows上使用Android Studio导入,进行查看和修改,修改完成后通过Beyondcompare工具将修改的内容同步到Linux平台进行编译等工作。这个各方面折中的方案。后续主要介绍这种工作环境的配置。
安装配置Linux环境
如果已经有Linux机器,本步骤省略。我在家中没有,遂采用在Windows上安装Virtualbox,然后通过Virtualbox安装Linux(Ubuntu)。 同时按需安装Git/Vim/OpenSSH Server等工具,安装方式不再赘述,网上有很多。
下载AOSP源码
在配置好的Linux环境中下载AOSP源码,Google官方的下载AOSP源码的方式:https://source.android.com/docs/setup/build/downloading。 但是由于墙的原因,这种方式不容易实现,所以推荐使用清华的镜像,使用指导:https://mirrors.tuna.tsinghua.edu.cn/help/AOSP/。 Repo的使用方式可以参考:Repo实践指南:https://www.cnblogs.com/jiangxinnju/p/14274982.html
配置Windows上的工具
1、 安装SSH客户端工具,这里推荐MobaXTerm,因为它不仅免费还自带了rsync命令行工具,可以非常方便从Linux上同步代码到Windows。 a) mkdir -p /drives/d/Code/sync/aosp/frameworks b) rsync -az –progress –delete –exclude=”.git” android@192.168.1.125:/home/android/aosp/frameworks/base /drives/d/Code/sync/aosp/frameworks/ c) rsync -az –progress –delete –exclude=”.git” android@192.168.1.125:/home/android/aosp/frameworks/native /drives/d/Code/sync/aosp/frameworks/ 2、 安装BeyondCompare工具,方便对比,将修改的代码同步到Linux环境。 3、 安装Android Sudio,将AOSP源码导入到Android Studio进行查看:https://www.cnblogs.com/jiangxinnju/p/14426645.html 4、 安装Source Insight工具,AS查看AOSP的Java代码比较合适,但是C/C++代码不支持跳转,着色也比较差,看这部分代码还是SI比较好用。
TensorFlow环境搭建
预备条件
Ubuntu 22.04.2 LTS 配置好固定IP,安装SSH(Server)/Samba等基础网络连接软件
腾讯云环境构建
开启root用户
sudo passwd root
修改主机名
sudo vim /etc/hostname 修改成ubuntu sudo reboot
防止SSH经常断连
ubuntu@ubuntu:~$ sudo vim /etc/ssh/sshd_config ClientAliveInterval 30 ClientAliveCountMax 86400
ubuntu@ubuntu:~$ sudo /etc/init.d/ssh restart
安装JDK 8
ubuntu@ubuntu:/usr/local$ sudo mkdir java ubuntu@ubuntu:/usr/local$ sudo chown ubuntu:ubuntu java
上传jdk-8u371-linux-x64.tar.gz到java目录
ubuntu@ubuntu:/usr/local$ cd java/ ubuntu@ubuntu:/usr/local/java$ tar -zxvf jdk-8u371-linux-x64.tar.gz
ubuntu@ubuntu:/usr/local/java $ cd ubuntu@ubuntu:~$ sudo vim /etc/profile
在文件末尾添加如下内容:
export JAVA_HOME=/usr/local/java/jdk1.8.0_371 export CLASSPATH=.:$JAVA_HOME/lib:$CLASSPATH export PATH=$JAVA_HOME/bin:$PATH
ubuntu@ubuntu:~$ source /etc/profile ubuntu@ubuntu:~$ java -version java version “1.8.0_371” Java(TM) SE Runtime Environment (build 1.8.0_371-b11) Java HotSpot(TM) 64-Bit Server VM (build 25.371-b11, mixed mode)
安装JDK 17
ubuntu@ubuntu:/usr/local$ sudo mkdir java ubuntu@ubuntu:/usr/local$ sudo chown ubuntu:ubuntu java
上传jdk-8u371-linux-x64.tar.gz到java目录
ubuntu@ubuntu:/usr/local$ cd java/ ubuntu@ubuntu:/usr/local/java$ tar -zxvf jdk-17_linux-x64_bin.tar.gz
ubuntu@ubuntu:/usr/local/java $ cd ubuntu@ubuntu:~$ sudo vim /etc/profile
在文件末尾添加如下内容:
export JAVA_HOME=/usr/local/java/jdk-17.0.7 export PATH=$JAVA_HOME/bin:$PATH
ubuntu@ubuntu:~$ source /etc/profile ubuntu@ubuntu:~$ java -version java 17.0.7 2023-04-18 LTS Java(TM) SE Runtime Environment (build 17.0.7+8-LTS-224) Java HotSpot(TM) 64-Bit Server VM (build 17.0.7+8-LTS-224, mixed mode, sharing)
安装Tomcat 8.5
ubuntu@ubuntu:/usr/local$ sudo mkdir tomcat ubuntu@ubuntu:/usr/local$ sudo chown -R jiangxin:jiangxin tomcat ubuntu@ubuntu:/usr/local$ cd tomcat/ ubuntu@ubuntu:/usr/local/tomcat$ tar -zxvf apache-tomcat-8.5.88.tar.gz ubuntu@ubuntu:/usr/local/tomcat$ cd
ubuntu@ubuntu:~$ sudo vim /etc/profile
export CATALINA_BASE=/usr/local/tomcat/apache-tomcat-8.5.88 export CATALINA_HOME=/usr/local/tomcat/apache-tomcat-8.5.88 export PATH=$PATH:$CATALINA_HOME/lib:$CATALINA_HOME/bin
ubuntu@ubuntu:~$ source /etc/profile
本次会话启动tomcat startup.sh ; tail -f $CATALINA_HOME/logs/catalina.out
后台启动tomcat nohup startup.sh &
关闭tomcat shutdown.sh
端口占用查询 sudo netstat -tulpn | grep 8080
进程查询 ps -ef | grep tomcat
在浏览器中访问下面地址,查看能否正常访问:
http://124.222.145.48:8080/
安装Tomcat 9
ubuntu@ubuntu:/usr/local$ sudo mkdir tomcat ubuntu@ubuntu:/usr/local$ sudo chown -R jiangxin:jiangxin tomcat ubuntu@ubuntu:/usr/local$ cd tomcat/ ubuntu@ubuntu:/usr/local/tomcat$ tar -zxvf apache-tomcat-9.0.75.tar.gz ubuntu@ubuntu:/usr/local/tomcat$ cd
ubuntu@ubuntu:~$ sudo vim /etc/profile
export CATALINA_BASE=/usr/local/tomcat/apache-tomcat-9.0.75 export CATALINA_HOME=/usr/local/tomcat/apache-tomcat-9.0.75 export PATH=$PATH:$CATALINA_HOME/lib:$CATALINA_HOME/bin
ubuntu@ubuntu:~$ source /etc/profile
本次会话启动tomcat startup.sh ; tail -f $CATALINA_HOME/logs/catalina.out
后台启动tomcat nohup startup.sh &
关闭tomcat shutdown.sh
端口占用查询 sudo netstat -tulpn | grep 8080
进程查询 ps -ef | grep tomcat
在浏览器中访问下面地址,查看能否正常访问:
http://124.222.145.48:8080/
安装Tomcat 10
ubuntu@ubuntu:/usr/local$ sudo mkdir tomcat ubuntu@ubuntu:/usr/local$ sudo chown -R jiangxin:jiangxin tomcat ubuntu@ubuntu:/usr/local$ cd tomcat/ ubuntu@ubuntu:/usr/local/tomcat$ tar -zxvf apache-tomcat-10.1.9.tar.gz ubuntu@ubuntu:/usr/local/tomcat$ cd
ubuntu@ubuntu:~$ sudo vim /etc/profile
export CATALINA_BASE=/usr/local/tomcat/apache-tomcat-10.1.9 export CATALINA_HOME=/usr/local/tomcat/apache-tomcat-10.1.9 export PATH=$PATH:$CATALINA_HOME/lib:$CATALINA_HOME/bin
ubuntu@ubuntu:~$ source /etc/profile
本次会话启动tomcat startup.sh ; tail -f $CATALINA_HOME/logs/catalina.out
后台启动tomcat nohup startup.sh &
关闭tomcat shutdown.sh
端口占用查询 sudo netstat -tulpn | grep 8080
进程查询 ps -ef | grep tomcat
在浏览器中访问下面地址,查看能否正常访问:
http://124.222.145.48:8080/
安装MySQL
root@ubuntu:~# mkdir /usr/local/mysql root@ubuntu:~# cd /usr/local/mysql/ root@ubuntu:/usr/local/mysql# groupadd mysql root@ubuntu:/usr/local/mysql# useradd -r -g mysql -s /bin/false mysql root@ubuntu:/usr/local/mysql# tar zxvf mysql-5.7.19-linux-glibc2.12-x86_64.tar.gz root@ubuntu:/usr/local/mysql# cd mysql-5.7.19-linux-glibc2.12-x86_64/ root@ubuntu:/usr/local/mysql/mysql-5.7.19-linux-glibc2.12-x86_64# mkdir mysql-files root@ubuntu:/usr/local/mysql/mysql-5.7.19-linux-glibc2.12-x86_64# chmod 750 mysql-files root@ubuntu:/usr/local/mysql/mysql-5.7.19-linux-glibc2.12-x86_64# chown -R mysql . root@ubuntu:/usr/local/mysql/mysql-5.7.19-linux-glibc2.12-x86_64# chgrp -R mysql . root@ubuntu:/usr/local/mysql/mysql-5.7.19-linux-glibc2.12-x86_64# bin/mysqld –initialize –user=mysql 2023-05-19T14:53:42.895566Z 0 [Warning] TIMESTAMP with implicit DEFAULT value is deprecated. Please use –explicit_defaults_for_timestamp server option (see documentation for more details). 2023-05-19T14:53:42.895679Z 0 [ERROR] Can’t find error-message file ‘/usr/local/mysql/share/errmsg.sys’. Check error-message file location and ‘lc-messages-dir’ configuration directive. 2023-05-19T14:53:43.307387Z 0 [Warning] InnoDB: New log files created, LSN=45790 2023-05-19T14:53:43.391326Z 0 [Warning] InnoDB: Creating foreign key constraint system tables. 2023-05-19T14:53:43.460485Z 0 [Warning] No existing UUID has been found, so we assume that this is the first time that this server has been started. Generating a new UUID: f319f8fa-f654-11ed-96fb-525400468e37. 2023-05-19T14:53:43.467893Z 0 [Warning] Gtid table is not ready to be used. Table ‘mysql.gtid_executed’ cannot be opened. 2023-05-19T14:53:43.468453Z 1 [Note] A temporary password is generated for root@localhost: /2jW>kFeerno root@ubuntu:/usr/local/mysql/mysql-5.7.19-linux-glibc2.12-x86_64# bin/mysql_ssl_rsa_setup
root@ubuntu:/usr/local/mysql/mysql-5.7.19-linux-glibc2.12-x86_64# sudo vim /etc/profile
export MYSQL_HOME=/usr/local/mysql/mysql-5.7.19-linux-glibc2.12-x86_64 export PATH=$PATH:$MYSQL_HOME/bin
root@ubuntu:/usr/local/mysql/mysql-5.7.19-linux-glibc2.12-x86_64# source /etc/profile
root@ubuntu:/usr/local/mysql/mysql-5.7.19-linux-glibc2.12-x86_64# cd root@ubuntu:~# mysqld_safe –user=mysql & [1] 1931893 root@ubuntu:~# Logging to ‘/usr/local/mysql/data/ubuntu.err’. 2023-05-19T15:00:22.730000Z mysqld_safe Starting mysqld daemon with databases from /usr/local/mysql/data root@ubuntu:~# mysql -u root -p [1] 1931893 root@ubuntu:~# Logging to ‘/usr/local/mysql/data/ubuntu.err’. 2023-05-19T15:00:22.730000Z mysqld_safe Starting mysqld daemon with databases from /usr/local/mysql/data
root@ubuntu:~# mysql -u root -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 3 Server version: 5.7.19
Copyright (c) 2000, 2017, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners.
Type ‘help;’ or ‘\h’ for help. Type ‘\c’ to clear the current input statement.
mysql> exit Bye root@ubuntu:~# mysqladmin -uroot -p’/2jW>kFeerno’ password test mysqladmin: [Warning] Using a password on the command line interface can be insecure. Warning: Since password will be sent to server in plain text, use ssl connection to ensure password safety. root@ubuntu:~# mysql -u root -p Enter password: Welcome to the MySQL monitor. Commands end with ; or \g. Your MySQL connection id is 5 Server version: 5.7.19 MySQL Community Server (GPL)
Copyright (c) 2000, 2017, Oracle and/or its affiliates. All rights reserved.
Oracle is a registered trademark of Oracle Corporation and/or its affiliates. Other names may be trademarks of their respective owners.
Type ‘help;’ or ‘\h’ for help. Type ‘\c’ to clear the current input statement.
mysql> select user, host from mysql.user;
+—————+———–+
| user | host |
+—————+———–+
| mysql.session | localhost |
| mysql.sys | localhost |
| root | localhost |
+—————+———–+
3 rows in set (0.00 sec)
mysql> update mysql.user set host = ‘%’ where user = ‘root’; Query OK, 1 row affected (0.00 sec) Rows matched: 1 Changed: 1 Warnings: 0
mysql> flush privileges; Query OK, 0 rows affected (0.00 sec)
mysql> exit Bye
部署项目
war包放到$CATALINA_HOME/webapps/目录下,然后重启tomcat shutdown.sh; startup.sh ; tail -f $CATALINA_HOME/logs/catalina.out
http://124.222.145.48:8080/JavaWebTest/index.jsp
MyEclipse 2014安装说明
下载过程就不详述了。
说明一下,可以只安装MyEclipse 2014,而不用提前安装JDK、Eclipse、Tomcat等软件,MyEclipse 2014内嵌了这些东西,网上说的MyEclipse只是Eclipse的插件,所以要安装MyEclipse就要先安装Eclipse,而要安装Eclipse又必须提前安装JDK。这对于旧版本的MyEclipse来说确实是这样,但是对于比较新的几个版本来说,不需要了,MyEclipse包含了开发所需要的大多数工具。
当然,如果你不想使用其自带的JDK或者服务器软件,你可以在安装了其它的JDK版本和服务器软件之后自行设置。(在Window->Preferences中进行配置)


安装好之后,先不要打开MyEclipse 2014的程序。
接下来对MyEclipse进行破解,由于破解包是jar包,所以需要JRE,不过一般的机子上都有,可以打开CMD输入java命令测试一下,如果显示以下命令则证明本机已有JRE,无需安装,如果没有下载JRE,进行安装。
打开破解文件夹,运行cracker.jar。在破解界面中,usercode随便输入,然后点击右边的SystemId按钮,将在SystemId中自动生成一串机器码。
然后选择Tools->RebuildKey。
点击激活按钮。将会看到有日志生成。
选择Tools->ReplaceJarFiles。选择MyEclipse安装目录中的Plugin文件夹。
操作Tools->SaveProperities
重新打开MyEclipse 2014
MyEclipse->Subscription Informatioon,显示激活。
Comments