
Java 性能分析工具,第 2 部分:Java 内置监控工具
使用 Java 内置监控工具将程序运行状况和 JVM 信息以直观的方式展现以便于分析
前言
本文为 Java 性能分析工具系列文章第二篇, 第一篇:操作系统工具 。在本文中将介绍如何使用 Java 内置监控工具更加深入的了解 Java 应用程序和 JVM 本身。在 JDK 中有许多内置的工具,其中包括:
- jcmd:打印一个 Java 进程的类,线程以及虚拟机信息。适合用在脚本中。使用 jcmd – h 来查看使用方法。
- jconsole:提供 JVM 活动的图形化展示,包括线程使用,类使用以及垃圾回收(GC)信息。
- jhat:帮助分析内存堆存储。
- jmap:提供 JVM 内存使用信息,适用于脚本中。
- jinfo:访问 JVM 系统属性,同时可以动态修改这些属性。
- jstack:提供 Java 进程内的线程堆栈信息。
- jstat:提供 Java 垃圾回收以及类加载信息。
- jvisualvm:监控 JVM 的可视化工具,剖析运行中的应用程序,分析 JVM 堆存储。
下面将根据功能划分来详细介绍这些工具。
VM 基本信息
JVM 工具能够提供一个运行中的 JVM 进程的基本信息,例如运行时间、使用中的 JVM 参数以及 JVM 系统属性。
-
uptime
JVM 运行的时间,jcmd process_id VM.uptime
-
system properties
通过 System.getProperties() 可以得到的系统属性也可以通过下面的命令获得:
jcmd process_id VM.system_properties 或者 jinfo –sysprops process_id
这些属性包括所有通过命令行-D 选项设置的属性、应用程序动态添加的属性和 JVM 的默认属性。
-
JVM version
通过 jcmd process_id VM.version 获得。
-
JVM command line
JVM 命令行可以在 jconsole 中的 VM summary 中找到,或者通过 jcmd process_id VM.command_line 命令获得。
-
JVM 调优参数
通过命令 jcmd process_id VM.flags [-all] 命令或者所有生效的调优参数获得。
使用调优参数(Tuning Flags)
由于调优参数非常繁多,需要借助 JVM 命令行和 JVM 调优参数来使用。使用 command_line 命令可以获得命令行中指定的调优参数,flags 命令可以获得通过命令设置的调优参数和 JVM 设置的调优参数。
通过 jcmd 命令可以获得一个运行中 JVM 内生效的调优参数。通过下面这条命令可以获得一个指定平台内生效的调优参数。
java other_options –XX:+PrintFlagsFinal –version
Show moreShow more icon
我们需要把其他选项同时包含在这条命令中,尤其是设置了 GC 相关的调优参数。这条命令的部分输出如下所示,第一行中的冒号说明第一行的调优参数使用的不是默认值,而是以下三种方式设置:
-
通过命令行设置
其他选项间接改变了此调优参数的值
-
JVM 计算出默认值
第二行由于没有包含冒号,说明此行的调优参数为当前 JVM 版本的默认值,最后一列的 product 说明此行的调优参数的值在不同平台相同,而 pd product 说明此行的调优参数的值依赖于平台。
uintx InitialHeapSize := 4169431040 {product} intx InlineSmallCode = 2000 {pd product}Show moreShow more icon
最后一列的其他选项:
manageable:此 flag 的值可以在运行时动态改变 c2 diagnostic:此 flag 提供帮助工程师理解的编译器如何工作的帮助信息。Show moreShow more icon
jinfo 命令可以查看某个单一 flag 的值,通过下面的命令:
jinfo -flag PringGCDetails process_id –XX:+PrintGCDetailsShow moreShow more icon
-
通过下面的命令可以设置某个 flag 的 manageable 属性来控制其能否在运行时被改变:
jinfo -flag -printgcdetails process_id # 关闭 PrintGCDetails 的 manageable 属性
尽管 jinfo 命令可以改变任何 flag 的值,但不能确定 JVM 会接受这些改变。例如很多影响垃圾回收算法执行的 flag 都会在 JVM 启动时被设置,在 JVM 运行过程中通过 jinfo 命令修改 flag 的值并不会影响算法执行。所有此命令只对那些 manageable 为真的 flag 起作用。
线程信息
jconsole 和 jvisualvm 命令可以帮助开发人员剖析应用程序运行过程中线程的相关信息。通过 jstack process_id 命令可以查看线程的运行时栈信息,可以明确获得当前线程是否被阻塞。通过命令 jcmd process_id Thread.print 可以获得相同结果。
类信息
通过 jconsole 和 jstat 命令可以获得应用程序运行过程中的所有类的相关信息,同时 jstat 命令也提供了类编译的相关信息。
垃圾回收信息
Jconsole 展示了 JVM 堆使用的情况,它所绘制的的动态图能够帮助开发人员了解堆的内部情况。jcmd 支持垃圾回收操作。jmap 提供堆信息总览。jstat 从不同的角度展示垃圾回收是如何工作的。
Heap Dump 文件的后序处理
通过 jvisualvm 用户界面可以得到 Heap Dump 文件,通过 jcmd 和 jmap 也可以获得。Heap Dump 文件是堆的快照,一般使用 jvisualvm 和 jhat 来分析这个快照。
性能分析工具
Java 提供的性能分析器是最重要的分析工具。它的种类繁多,各有所长,使用不同的分析器在分析同一个应用时可能会发现不同的问题。在使用过程中需要各取所长,这样才能对应用进行全面的分析。
基本上所有的 Java 性能分析器都是用 Java 实现的,通过套接字(socket)与被分析应用进行通信来获得被分析应用的运行信息。需要注意的是,在使用性能分析工具调优被分析应用的同时,需要关注性能分析器其自身的性能。假如当被分析的应用程序产生十分庞大的信息,而将其发送至性能分析器时,如果性能分析器没有空间充分管理高效的内存堆来处理这些信息时,分析将无法进行。采用并行垃圾回收算法进行内存管理是当前性能分析器比较流行的做法,这种算法能够最大程度地降低内存溢出的可能。
性能分析分为采样模式和检测模式。下面将分别介绍这两种模式。
采样分析
采样模式是性能分析中最常用的模式,因为其对被分析应用程序影响最小,这一点非常重要。只有当性能分析过程对应用程序的影响降到最低,才能获得有价值的性能分析结果。
在采样分析模式中,分析器被定时触发工作。在工作周期内,分析器依次检查每个线程并记录线程中正在运行的方法,在某些特定场景下,采样分析往往会带来错误的分析结果。例如,在图 1 中,某线程在一段时间内交替执行方法 A 和方法 B,每次当分析器被触发工作时,该线程都恰好在执行方法 B,那么分析器会认为该线程的所有时间都是在执行方法 B,但是事实并非如此,该线程执行方法 A 的时间远大于执行方法 B 的时间,只是并未被分析器采样到。
图 1. 某一时间段内线程交替执行方法 A 和 B 示例图
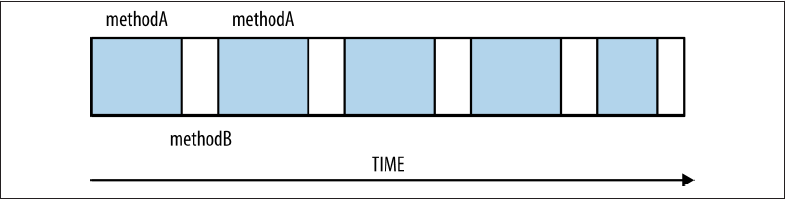
这是采样模式中最常见的错误,通过增加采样分析器的采样时间隔可以帮助我们有效的减少这类错误的发生,因为时间间隔太小往往会增加采样分析器对被分析的应用程序产生性能方面的影响,从而导致分析结果失真。所以时间间隔需要根据被分析应用的特点通过多次的试验以及经验来决定,权衡过大或过小的影响之后设定。
图 2. 采样模式分析示例图
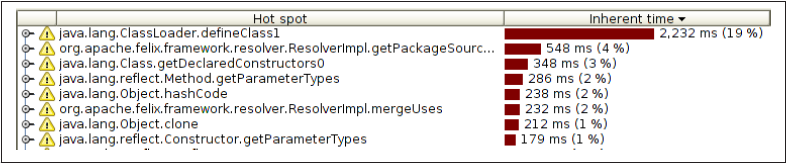
图 2 所示是使用采样模式分析一个应用服务器 GlassFish 启动过程的结果。从图中可以看到,方法 defineClass1() 使用了 19%的时间,接下来是方法 getPackageSourceInternal(),占用了 10%的时间。Java 应用程序中定义的类会影响应用程序启动过程中的性能表现,为了提高应用程序的启动速度,就必须通过提高类加载的速度,从而达到提升启动速度的目标。从图中我们可能会错误的认为要改善性能的方法是 defineClass1(),但是 defineClass1() 其实是 JDK 中的方法,我们不可能通过重写 JVM 来提高它的性能。即使重写此方法将其执行时间优化至原有时间的 60%,也只能减少 10%应用程序整体运行时间,这显然得不偿失。
检测分析
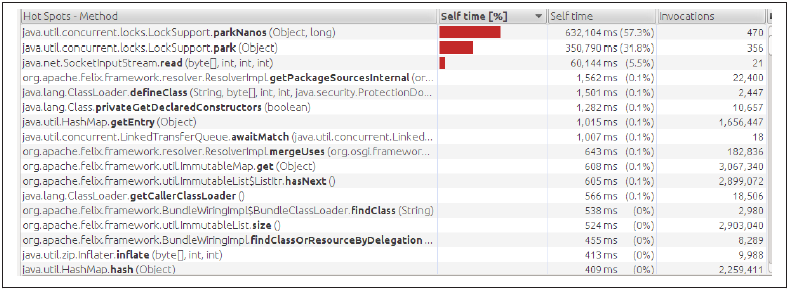
相比于采样模式,检测模式是要侵入被分析的应用程序内部,虽然这样做并不是高效、友好的,但它却可以获得非常有价值的信息。图 3 为使用相同分析工具的检测模式分析相同应用服务器 GlassFish 的结果。
图 3. 检测分析示例图

在图中有以下几点信息:
- 最耗时的方法为 getPackageSourcesInternal(), 占用了 13%的时间,而并非在采样模式中得到的 4%;
- 方法 defineClaass1() 并未出现在分析结果中。
- 分析结果中包括每个方法执行的次数和平均耗时。
这些分析结果中的信息对于发现耗时多的代码是非常有帮助的。在本例中,尽管方法 ImmutableMap.get() 消耗 12%的时间,但是它被调用了四百七十万次之多。如果减少此方法的调用次数,应用的性能将会得到大幅度提升。
检测分析器在类被加载时通过改变其字节码顺序来获取应用运行数据,例如增加记录方法被调用次数的代码。相比于采样模式,这种方式会更大程度的影响应用本身的性能。例如,JVM 会根据方法的代码块大小,将方法体很小的方法内联化,这样在内联方法执行时就不会进行方法调用。在检测分析器在内联方法中加入其代码后,此方法因为方法体过大并未被 JVM 内联化,由此造成此方法的耗时被放大。内联化只是一个例子,当越来越多的代码被改变的时候,分析的结果失真的概率就会比较大。
造成方法 ImmutableMap.get() 没有出现在采样模式分析结果中的原因是安全点(safepoint)的存在。只有当一个线程获得的内存大于安全点时,采样分析器才会对其进行分析。因为方法 ImmutableMap.get() 所在线程一直没有达到安全点,所以在结果中不会出现。当使用采样模式安全点过高时,会低估一些方法对性能的影响。
在本例中,无论是采样分析还是检测分析,都能发现应用的性能瓶颈在于类的加载和解析。但是在实际中,不同的分析器不可能得出完全相同的分析结果。分析器擅长估量,但也只是估量,一些误差甚至是错误不可避免,所以在性能分析过程中还需要我们更加灵活的使用分析器。
阻塞方法和线程的时间轴
如图 4 所示为使用 NetBeans Profiler(另一种检测分析器)分析上述应用服务器 GlassFish 启动过程的结果展示。在此结果中,方法 park(),parkNanos() 和 read() 占用了绝大多数的应用运行时间。这些方法都是被阻塞的方法,并不消耗 CPU,所以在计算应用的 CPU 使用率时这些时间不应计入。应用中的线程并没有使用 632 秒来执行 parkNanos() 方法,而是等待其他操作完成花费 632 秒。park() 和 read() 方法与此同理。
图 4. NetBeans 检测分析示例图
因此,大多数的分析器都不会将被阻塞的方法和闲置的线程计入结果。在 NetBeans 中,可以设置分析结果包含所有的方法,所以在本例中这些方法被计入结果。在本例中,执行 park() 方法的线程位于服务器线程池中,当服务器接收到请求时,这些线程处理请求。当没有请求时,这些线程处于阻塞状态,等到新的请求,并不占用 CPU。这是应用服务器的正常状态。
绝大多数的基于 Java 的分析器都可以提供过滤器功能来查看或者隐藏被阻塞方法调用的时间,如果需要可以使用该功能。通常情况下,查看线程的运行状况比查看被阻塞方法的阻塞时间更加有帮助。
图 5. Oracle Solaris Studio 中线程的运行示例图

图 5 为在 Oracle Solaris Studio 中一个线程的运行情况。每一个水平区域代表一个不同的线程,所以上图中有两个线程(1.3 和 1.2)。不同颜色的柱子代表执行的不同方法;空白处代表该线程没有执行任何方法。综合来看,线程 1.2 先执行了一段代码然后等待线程 1.3 完成执行,线程 1.3 完成执行后等待线程 1.2 执行另一段代码。深入下去可以发现这些线程如何进行交互。
图中存在一些没有线程执行的空白区域,这是因为图中只展示了其中的两个线程,所以在那段空白区域是图中所示两个线程在等待其他线程执行完成。
本地分析器
本地分析器是用来分析 JVM 本身的工具。通过本地分析器可以观察到 JVM 正在进行的操作或者查看是否有应用程序包含了 JVM 的本地库,也可以观察到代码内部。任何本地分析器都可以分析使用 C 语言实现的 JVM(包括所有本地库),但是一些本地分析其不能分析使用 Java 和 C++实现的应用。
图 6. 本地分析器分析示例图
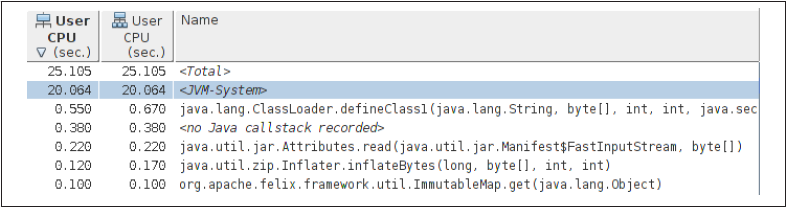
图 6 中展示了使用 Oracle Solaris Studio 分析器中分析 GlassFish 启动过程的结果。Oracle Solaris Studio 是一个可以分析 Java 和 C++的本地分析器。从图中可以发现,应用消耗的 CPU 时间为 25.1 秒。其中 JVM-System 消耗 20 秒,包括 JVM 编译器线程,垃圾回收线程以及一些辅助线程。由于在启动过程中需要编译非常多的代码,所以 JVM 编译器线程消耗了绝大多数时间,而垃圾回收线程只消耗了很少的时间。
通过本地分析器我们不仅可以分析优化 JVM 自身功能,更重要的是可以获得应用程序进行垃圾回收的时间。在 Java 分析工具中,垃圾回收线程的信息是无法得到的。
分析过 JVM 本地代码后,我们将对应用程序的启动过程进行分析。如图 7 所示,继在采样模式分析后,方法 defineclass1() 又一次被分析为最耗时的方法。值得关注的是,再次分析结果中,解压读取 jar 文件的方法耗时相对较多。类加载中会用到这些方法,所以证明优化的方向是正确的。由于 Java zip 库中引用的本地代码在其他分析工具中被作为阻塞方法调用,所以在上文各类工具中并没有发现此方法。
图 7. 采样模式分析示例图
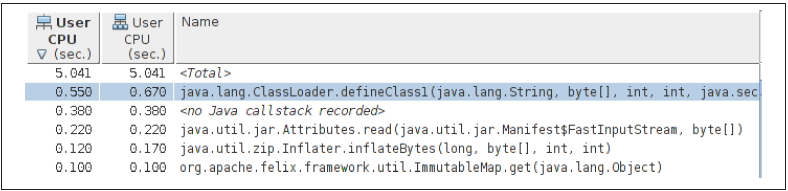
无论使用何种性能分析工具,最重要的是熟悉每种工具的优势和劣势。这样才能取长补短,配合使用。开发人员必须学会如何使用性能分析器来找到性能瓶颈,找到需要优化的代码,而不是单纯的关注最耗时的个别方法。
结束语
基于采样的性能分析是最常见的一种,因为其相对能做到的分析是有限的,亦或者分析过程所能搜集到的信息是概述性的,往往并不能真实表现应用程序内部的运行情况,但是其分析过程中引入的工作量通常是较低的。不同的采样分析工具行为是不同的,充分利用其优势,做有针对性的分析才是最有意义的。
检测分析能够获得非常多的有关应用程序内部信息,但是前期准备工作往往是非常大的。检测分析方法应当尽量应用在一小节代码中,或者少数几个类、包中。这种方法其实一定程度上限制了对整体应用程序的性能分析,仅适合在程序单元中使用,点对点,针对性较强的分析,采用检测分析的时候,更多时间要求开发人员明确知道哪里有可能产生性能瓶颈。
线程阻塞不一定就是代码编写而产生的,发生线程阻塞时,更多的建议是去想,去看为什么会被阻塞,而不是直接查看代码。尽量采用线程执行时间轴的分析方法。
本地分析提供了既可以深入查看 JVM 内部,同时也可以查看应用程序代码执行的情况。
如果本地分析显示在 GC 过程中大量的使用 CPU 资源,那么调优收集器就是必要的。需要提醒大家的是,编译线程通常是不影响应用程序的性能。
李伟军, 宋翰瀛, 杨翔宇
发布: 2016-08-23
Comments